관계형 데이터 모델링 노트 : 01 엔티티 이야기
Chapter 1 : 엔티티 이야기
서론
- 해당 포스팅은 아래 서책을 기준으로 이론 스터디를 진행한 부분을 정리한 포스팅이다. 책의 내용을 인용하여 내 생각을 정리해 보았다.
- 모델링에 관심 많은 사람들은 아래 링크를 통해 김기창 대표님의 “관계형 데이터 모델링 노트”를 구매하여 보는것을 추천하고, 책 외적으로 카페 활동이나 스터디 활동을 왕성하게 하고 계시는 분이라서 혹시 모델링 관련 스터디에 참여하고 싶은 사람은 아래 카페에 가입하는 것도 추천드립니다.

집합과 엔티티
- 게오르 칸토어가 얘기한 집합의 정의는 "우리의 직관 또는 사고의 대상으로 확정되어 있고 서로 명확히 구별되는 것들의 모임" 이다.
- 이는 명확한 조건이 기준이 되어야 집합이 될수 있다는 의미로 예를 들어 “프로 야구 강팀의 모임” 이라고 하면 명확한 기준이 없기 때문에 집합이 아니다. 하지만 “우승해본 팀들의 모임” 이라고 하면 명확한 기준이 있기에 집합이라고 정의할 수 있다.
- 이 또한 엔티티에 적용하면 엔티티도 명확한 기준이 되는 틀(조건)이 있어야 엔티티의 경계를 구분하여 엔티티를 정의할 수 있다는 의미이다. 이처럼 엔티티를 정확하게 정의하는 것이 모델링의 최고 중요한 부분이라고 할 수 있다.
엔티티에 대한 서설
- 업무적으로 접근하여 엔티티를 정의한다면, "업무를 수행하는데 필요한 데이터를 유사한 것끼리 모아놓은 집합" 이라고 할 수 있다. 여기서 말하는 유사한 특성은 함수 종속성(Functional Dependency) 와 연관되어 있다.
- 엔티티 판단 기준
- 해당 엔티티가 관리하고자 하는 데이티인가?
- 식별자가 존재하는가?(유일하게 식별 가능한가?)
- 엔티티 정의가 중요한 이유
- 엔티티가 모데링의 시발점이기 때문에 엔티티 정의가 중요한 것은 당연하다. 엔티티 정의를 잘못하면 그 이후의 단계는 당연히 잘못한 것으로 의미가 없다.
엔티티 분류법
- 만질 수 있는 것과 만질 수 없는것.
- 자립 엔티티와 종속 엔티티
- 원천 데이터와 가공 데이터
- 실체, 행위, 가공, 기준 엔티티
- 내부 생성 데이터와 외부 생성 데이터
- 엔티티 유형에 의한 기본, 내역, 상세 등의 엔티티
엔티티 정의 방법 : 보이는 것 인가?
- 보이는 것을 관리하는 엔티티는 실체 엔티티를 의미한다. 예를 들면 고객, 노트북, 상품, 자동차 등을 관리하는 엔티티가 보이는 것을 관리하는 엔티티이다. 보이는 실체는 물리적으로 존재하기 때문에 그 대상의 개수가 엔티티의 인스턴스 개수와 같다는 것이 가장 커다란 특성이다.
- 보이는 것을 의미하는 데이터는 핵심 데이터일 가능성이 높다. 실체 엔티티는 또한 다른 여러 행위의 주체가 되기 때문에 더욱 중요하다. 또한 보이는 것을 관리하는 엔티티는 많지 않다는 것도 특징이다.
엔티티 정의 방법 : 스스로 존재하는가?
- 자립 엔티티(Independent Eitity, Strong Entity, Domainant Entity)
- 다른 엔티티에 의존적이지 않고 스스로 존재하며, 어떤 에티티에도 존재 종속 되지 않는 엔티티.
- 다른 엔티티에 의존적이지 않고 스스로 존재하며, 어떤 에티티에도 존재 종속 되지 않는 엔티티.
- 종속 엔티티(Dependent Entity, Weak Entity, Subordinate Entity)
- 상위 엔티티가 존재 하지 않으면 존재할 수 없는 엔티티로서 어떤 엔티티에 존재 종속되지 않는다.
- 상위 엔티티가 존재 하지 않으면 존재할 수 없는 엔티티로서 어떤 엔티티에 존재 종속되지 않는다.
- 종속 엔티티의 종류
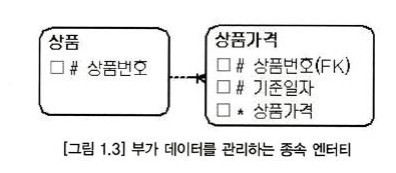
- 부모 엔티티의 부가 데이터를 관리하는 데이터
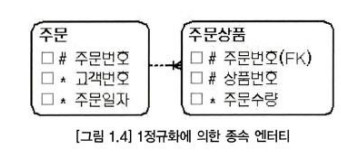
- 1정규화에 의해서 발생한 데이터
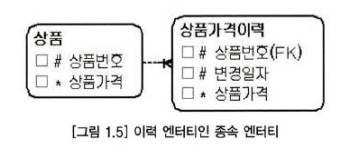
- 이력 데이터를 관리하는 엔티티
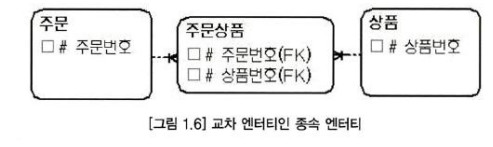
- 다대다 관계 에서 발생한 교차 엔티티
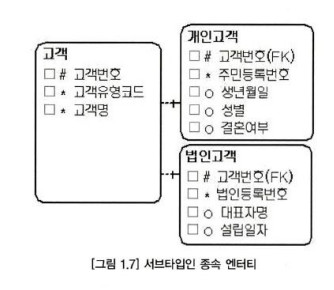
- 슈퍼 타입에 대한 서브타입 엔티티
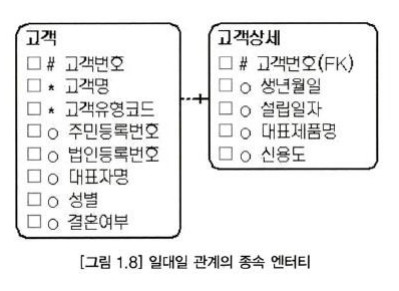
- 엔티티 분해에 의한 일대일 관게의 엔티티
- 부모 엔티티의 부가 데이터를 관리하는 데이터
엔티티 정의 방법 : 원천 데이터인가?
- 원천 데이터(Raw Data)는 스스로 존재하는 최초의 데이터이다. 반면에 가공 데이터(Processing Data)는 원천 데이터를 사용해서 만들어낸 구조다. 가공 데이터는 처음 데이터인 원천 데이터로 만들어낼 수 있지만, 또 다른 데이터로도 만들어낼 수 있다.
- 원천 데이터는 고객이나 사용자가 직접 입력함으로써 생성성된다. 즉, 화면에서 입력한다. 반면에 가공 데이터는 주로 프로그램에 의해 생성된다.
- 가공 데이터는 주로 업데이트가 발생하지 않는다. 누가, 어떻게, 언제, 생성 했느냐를 등의 부가 데이터는 업데이트가 발생할 수 있지만, 값을 관리하는 데이터는 스스로 업데이터가 발생하지 않고 원천이 바뀌면 따라서 업데이트해야 한다.
데이터 본질에 따른 엔티티 분류법 : 실체, 행위, 가공, 기준
- 실체 엔티티
- 실체 물체에 대한 본질적인 데이터를 관리하는 엔티티
- 실체 엔티티는 간단히 말해 만질 수 있는 것을 관리하는 엔티티이다.
- 실체 엔티티는 키 엔티티이거나 하위 엔티티가 많기 때문에 설계할 때 제일 중요한 엔티티이다.
- 실체 엔티티는 주 식별자가 간단한게 좋고, 통합을 고려하는것이 좋다.
- 행위 엔티티
- 행위나 활동으로 발생한 원천 데이터를 관리하는 엔티티
- 행위 엔티티는 어떤 실체의 업무 행위나 활동에 의해서 생긴 원천 데이터를 관리하는 엔티티이다. 엔티티 중에 가장 많은 엔티티이다.
- 행위 엔티티의 특징은 발생 순서가 존재할 수 있고, 속성이 많고, 주 식별자가 복잡하다는 것이다.
- 가공 엔티티
- 원천 데이터를 추출, 집계한 데이터를 관리하는 엔티티
- 원천 엔티티의 데이터를 가공한 데이터를 관리하는 엔티티로서 주로 집계/요약/임시 데이터를 관리한다.
- 가공 엔티티는 보통 집계 기준 역할을 하는 엔티티 이외의 엔티티와는 관계가 존재하지 않는다.
- 가공 엔티티의 주 식별자는 집계하려는 기준을 의미한다.
- 기준 엔티티
- 실체나 행위 데이터의 기준이 되는 데이터를 관리하는
- 기준 엔티티는 크게 두가지로 구분할 수 있다. 코드 데이터 처럼 기준 정보 성격의 데이터를 관리하는 엔티티가 있고, 과목 데이터처럼 기본 정보 성격의 데이터를 관리하는 엔티티가 있다.
- 보이는 것을 관리하는 실체 엔티티와 달리 개념적인 것을 관리하는게 다르다.
- 기준 엔티티를 제대로 설계하면 무엇보다 데이터 품질이 좋아진다.
엔티티 정의 방법 : 데이터 생성에 따른 분류법
- 데이터를 어디에서 생성되었는지에 따라 내부 데이터(Interal Data)와 외부 데이터(External Data)로 구분 할 수 있다.
- 내부 데이터는 내부에서 생성할 수 있는 데이터를 의미하고, 외부 데이터는 외부에서 받은 데이터로 내부에서 값이 맞고 틀리는지를 결정할 수 없다. 받은 그대로 관리하는 데이터이다.
엔티티 정의 방법 : 엔티티 유형에 따른 분류법
- 기본 엔티티 : 기본 엔티티는 기본적으로 실체 엔티티와 같다. 엔티티에 저장되는 데이터가 실제 물체를 의미하는 데이터라면 실체 엔티티며 기본 엔티티다.
- 내역 엔티티 : 내역 엔티티는 행위 엔티티와 유사하며 활동이나 행위에 의해 발생한 데이터를 관리하는 엔티티는 행위 엔티티이며 내역 엔티티다.
- 상세 엔티티 : 상세 엔티티는 한 개의 엔티티를 일대일 관계의 두 개의 엔티티로 분해할 때의 하위 엔티티를 의미한다. 이 엔티티는 중요 속성이 아닌 속성을 관리한다.
- 이력 엔티티 : 이력 엔티티는 이력을 관리하는 엔티티이다.
- 코드 엔티티 : 코드 엔티티는 코드 명과 코드를 관리하는 엔티티를 의미한다.
- 관계 엔티티 : 관계 엔티티는 교차 엔티티의 일종이다.
- 집계 엔티티 : 이력 엔티티와 마찬가지로 집계 엔티티 역시 집게라는 행위를 읨히가 때문에 “~ 집계”로 정해야 한다.
- 백업 엔티티 : 백업 엔티티는 원천 데이터를 백업한 엔티티를 의미한다.
- 임시 엔티티 : 사용한 후에 삭제하는 데이터를 임시 엔티티로 정할 수 있다.
엔티티 설계 원칙
- 엔티티를 설계하는 가장 중요하고도 원천적인 원칙은 성격, 본질, 주체에 따른 정체성이 분명한 엔티티로 설계해야 한다는 점이다.
- 데이터 정체성 : 엔티티를 명확하게 정의
- 엔티티 무결성 : 주 식별자가 존재하도록 설계
- 엔티티 유일성 : 같은 성격의 데이터는 전사적으로 유일
- 데이터 혼용배제 : 하나의 엔티티의 서로 다른 성격 데이터 혼용 사용 금지
- 타 엔티티와 관계 존재 : 어떤 엔티티와도 관계가 존재하지 않으면 확인 필요
- 프로세스 도출 지양 : 데이터 성격을 기준으로 엔티티를 생성하는것이 원칙
- 화면 도출 지양 : 화면은 View의 일종이므로 데이터 성격으로 기준으로 엔티티 생성하는 것이 원칙
- 데이터 관리 요건 : 데이터베이스에서 관리하고자 하는 데이터를 엔티티로 설계
엔티티 명은 어떻게 정하는가?
- 데이터 성격을 파악하기 쉽게 명명
- 일관성 있게 명명
- 구체적으로 명명
- 확장성을 고려하여 명명
- 필요한 단어로만 명명
- 프로세스를 표현하지 않도록 명명
- 명사형으로 명명
- 가능하면 짧게 명명
- 테이블 명이 엔티티명에 종속되지 않도록 명명
- 동일한 엔티티 명이 없도록 명명
다양한 엔티티에 대한 명명법
- 실체 엔티티 명명법 : 명사로 끝이 나도록 명명
- 행위 엔티티 명명법 : 명사로 끝나지 않도록 명명 -> (신청, 거래 등)
- 집계 엔티티 명명법 : 집계 기준을 앞, 대상을 뒤로 위치하는 것이 좋음
- 외부 엔티티 명명법 : 특정 기관에서 받는 데이터인 경우 해당 기관명을 엔티티 명에 추가
- 서브타입 엔티티 명명법 : 수퍼 타입 엔티티에 수식어를 붙이는 것이 좋음
- 일대일 관계 엔티티 명명법 : 데이터 성격에 맞는 수식어를 붙이는 것이 좋음
엔티티 정의의 또 다른 이름 : 업무 식별자
- 업무 식별자는 인스턴스의 개수를 늘리는 데 영향을 준다. 해당 엔티티에서 인스턴스가 늘어났다는 것은 데이터를 업무적으로 구분해서 사용하겠다는 것을 의미한다. 데이터를 쌓는 기준이 되는 것이 바로 업무 식별자이다.
- 업무 식별자를 중요하게 생각하는 이유는 이 엔티티의 성격을 표현하는 대표적인 속성이 업무 식별자이기 때문이다.
업무 식별자 도출 방법
- 업무 식별자는 엔티티의 인스턴스가 어떤 기준으로 생성되는지를 분석하면 찾을 수 있다. 또 다른 방법은 정규화를 수행하는 기준(결정자)를 찾는 것이다.
댓글남기기