[Cloud] : 06. MSA 설계
서론
- 이전 시간에는 MSA에 대한 기본 내용들에 대해서 알아 봤다. 이번 포스팅에서는 MSA 개발을 위해서는 필요한 부분과 필자가 MSA 개발하면서 생각했던 고민들에 대해서 포스팅해보겠다.
01. MSA 설계
1) MSA 설계 시 특징
-
MSA를 설계하기 위해서는 모널리틱 Application 보다 환경적으로 신경써야되는 부분들이 더 생긴다. 우선 이전 포스팅에서 얘기했던 MSA 특징 중 MSA 설계에서 특별히 중요한 특징에 대해서 부연 설명을 하자면 아래와 같다.
- 분리된 서비스들의 집합
- 우선 MSA의 가장 큰 특징으로는 하나 시스템 혹은 전사를 여러개의 서비스 단위로 나뉜다는 것이다. 이때 서비스를 어떻게 효율적으로 나눌것인가에 대한 부분이 중요하다.
- 우선 MSA의 가장 큰 특징으로는 하나 시스템 혹은 전사를 여러개의 서비스 단위로 나뉜다는 것이다. 이때 서비스를 어떻게 효율적으로 나눌것인가에 대한 부분이 중요하다.
- 똑똑한 엔드포인트와 파이프 처리
-
각 서비스들 끼리 통신을 하기 위해서는 각 서비스의 호출하기 위한 엔드포인트를 관리해야 된다. 이때 효율적인 엔드포인트 관리를 위해서 Netflix에서는 Eureka라는 Service Discovery와 Ribon이라는 Load balancer를 활용한다. 이부분은 아래에서 조금더 심도 있게 설명하겠다.
-
또한 각 서비스에 대한 베포 및 테스트와 같은 일련의 작업을 효율적으로 하기 위해서 파이프 라인을 통한 파이프 처리가 중요하다. 이부분은 DevOps와 관련이 있다.
-
- 통제/테이터 관리의 분권화
- 서비스 단위로 어플레이션을 구성한다는 것은 단지 기능/데이터 단위로만 구분한다는것이 아니다. 각 서비스 마다 통제와 데이터관리에 대한 권한을 위임한다는 의미이다. 한마디로 각 서비스는 하나의 시스템으로 역할과 권한을 지닌다는 의미이다.
- 서비스 단위로 어플레이션을 구성한다는 것은 단지 기능/데이터 단위로만 구분한다는것이 아니다. 각 서비스 마다 통제와 데이터관리에 대한 권한을 위임한다는 의미이다. 한마디로 각 서비스는 하나의 시스템으로 역할과 권한을 지닌다는 의미이다.
- 자동화된 환경 구축
- MSA에서 자동화된 환경 구축은 필수이다. MSA가 자동화되지 않는 환경을 사용한다는 것은 오히려 다수 관리 포인트와 유지보수에서 드는 비용이 더 든다는 결과로 이어질 뿐이다.
- MSA에서 자동화된 환경 구축은 필수이다. MSA가 자동화되지 않는 환경을 사용한다는 것은 오히려 다수 관리 포인트와 유지보수에서 드는 비용이 더 든다는 결과로 이어질 뿐이다.
02. 서비스 설계
-
이전에 설명했던거 처럼 MSA 설계를 위해서는 최우선적으로 생각해야될 부분이 각 서비스 설계이다. 이때 서비스를 어떤 단위로 나눌것인가는 명확하게 정해져있지 않다. 하지만 몇몇 기업에서 몇가지 기준 혹은 기존에 있는 모델링 기법을 통해서 정량적으로 서비스 설계를 할려고 했던 자료들이 있어 아래 정리해보았다.
-
아래 목록은 카카오 이모티콘 서비스를 MSA로 변환하면서 서비스 설계 원칙으로 정했던 부분 들이다. 참고하여 서비스 설계를 하면 좋을듯 하여 가지고 와봤다.
- 일정 크기 이하로 나눠야 한다 (Container 적재 용이)
- 되도록 기능 목적이 2개 이상이 되지 않도고록 한다.
- 여러 기능에서 사용하는 단위 리소스라면 서비스로 분리하여 공동 사용한다.
- 사내 통제 대상인 Admin인 경우, 최소한으로 통제 Cluster에 넣도록 서비스를 분리한다.
- 개인 정보 대상으로 분류된 데이터를 관리하는 서비스는 해당 데이터 관리에 필요한 기능을 최소화하여 분리한다.
1) 도메인 모델링
-
소프트웨어 공학에서는 “도메인 모델이란 특정 문제와 관련된 모든 주제의 개념 모델이다. 도메인 모델은 다양한 엔티티, 엔티티의 속성, 역할, 관계, 제약을 기술한다. 단 문제에 대한 솔루션을 기술하지 않는다.” 결국에는 도메인 모델링을 통해서 특정 문제/주제에 대한 모델을 작성하고 이를 토대로 서비스를 설계하는 것이다.
-
이러한 도메인 모델링을 통해서 MSA 서비스들을 설계하고 전체적인 소프트웨어 아키텍처에 대한 그림을 그릴 수 있는 기초 자료로서 활용 가능하다.
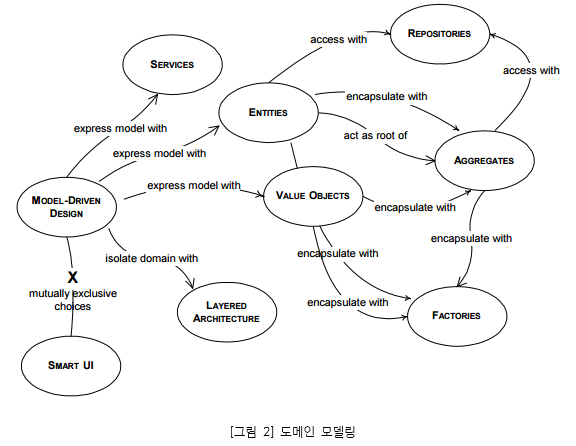
-
위의 그림은 도메인 모델링을 도식화한 것 이다. 각 요소별 의미는 아래와 같다.
- Value Object: 비즈니스 용어를 나타내는 불변 객체
- Entity: 속성이 아닌 식별성을 기준으로 정의되는 도메인 객체, 여러 Value Object로 구성(예: DB의 한 개 row)
- Service: 도메인 객체에 포함할 수 없는 오퍼레이션 연산을 갖는 객체
- Aggregate: 연관된 Value Object와 Entity의 묶음
- Factory: 복잡한 Entity, Aggregate를 캡슐화하여 여러 객체를 동시에 생성
- Repository: Aggregate의 영속성 및 등록·수정·삭제·조회 시 일관성 관리
2) Data Access 설계
-
MSA 서비스 설게 시 제일 중요한 부분 중에 하는 하나의 서비스는 하나의 DB에 엑세스 권한을 가진다는 것이다. 즉 다른 서비스가 관리하는 데이터에 필요하다면 해당 DB에 접속하는 것이 아니라 해당 서비스의 API 호출하여 데이터를 송신 받게 된다. 그렇기 때문에 각 서비스의 대한 DB 설계또한 중요하게 된다. 위에 얘기한 도메인 설계가 정확하게 된다면 한 서비스에 하나의 데이터 영역이 매핑되는 형태가 되어야 된다.
-
이렇게 되면 일반적인 RDB에 익숙한 사람들은 이러한 의문점을 가지게 될것이다. “조인은 어떻게 하지?”, “트랜잭션이 실패하면 Rollback은 어떻게 진행이 되지?”
-
우선 기본적으로는 조인이 많이 되는 테이블끼리는 같은 DB, 서비스에 있어야된다. 조인 많이 진행한다는 것은 같은 업무, 같은 도메인에 포함될 확률이 높다. 그렇기 때문에 자꾸 다른 테이블의 데이터를 가지고 위해서 다른 서비스를 호출한다면 다시 분석이 필요할 것이다. (여기서 공통은 제외)
-
두번째로 트랜잭션 처리이다. 서비스는 데이터 제공을 위한 API 개발 시 두가지를 동시에 개발해야된다. 첫째 기본적인 동작을 위한 API, 둘째 트랜잭션이 실패하였을때 보상 트랜잭션(Rollback)위한 API이다. 이렇게 하는것은 DB 레벨에서 트랜잭션을 처리가 불가능하기 때문에 어플리케이션 레벨에서 트랜잭션을 처리해줘야 된다. 이를 SAGA 패턴이라고 한다.
-
그리고 또 한가지 생각할 수 있는 부분이 있는데 바로 비정규화이다. 공통의 경우 모든 업무에서 많이 조인이 되는 데이터이다. 이를 매번 API 통해서 통신을 하게 되면 많은 트레픽이 공통에 집중될것이다. 이 또한 트레픽으로써 많은 금액이 발생할 수 있다. 이때 몇가지 기준에 따라서 각 서비스의 DB에 공통 테이블을 중복으로 가져가면 전체적인 트레픽을 줄일 수 있다. 기준은 아래와 같다. 이에 부합하다면 테이블을 중복테이블로 비정규화화여 성능적, 금액적으로 이득을 취할 수 있다.
- Update, Insert가 많이 없는 테이블이여한다.
- 전체 데이터의 크기가 크지 않아야한다.
- 데이터 변경이 발생하는 경우 모든 서비스의 DB에 동기화가 가능하도록 기능을 구현한다.
03. Service Mesh
-
Service Mesh란 애플리케이션의 다양한 부분들이 서로 데이터를 공유하는 방식을 제어하는 방법이다. 일반적인 어플리케이션과 다르게 MSA에 특화된 인프라 계층이다. 각 서비스 간의 통신을 제어하고 표시하고 관리할 수 있어야된다. 서비스 매쉬를 실제적으로 구현하기 위해서는 아래의 기능들이 필수적이다.
– Configuration Management: 서비스의 재빌드·재부팅 없이 설정 사항을 반영(Netflix Archaius, Kubernetes Configmap)
– Service Discovery: MSA 기반 서비스 배포 시 서비스 검색 및 등록(Netflix Eureka, Kubernetes Service, Istio)
– Load Balancing: 서비스간 부하 분산(Netflix Ribbon, Kubernetes Service, Istio)
– API Gateway: 클라이언트 접근 요청을 일원화(Netflix Zuul, Kubernetes Ingress)
– Service Security: 마이크로서비스 보안을 위한 심층 방어 메커니즘 적용(Spring Cloud Security)
– Centralized Logging: 서비스 별 로그의 중앙 집중화(ELK Stack)
– Centralized Monitoring: 서비스 별 메트릭 정보의 중앙 집중화(Netflix Spectator, Heapster)
– Distributed Tracing: 마이크로서비스 간의 호출 추적(Spring Cloud Sleuth, Zipkin)
– Resilience & Fault Tolerance: MSA 구조에서 하나의 실패한 서비스가 체인에 연결된 전체 서비스들에 파급 효과를 발생시키지 않도록 하기 위한 계단식 실패 방지 구조(Netflix Hystrix, Kubernetes Health check)
– Auto-Scaling & Self-Healing: 자동 스케일링, 복구 자동화를 통한 서비스 관리 효율화
– Build/Deploy Automation: 서비스 별 빌드·배포 자동화(Netflix Spinnaker, Kubernetes Scheduler, Jenkins)
– Test Automation: 서비스에 대한 테스트 자동화
– Image Repository: 컨테이너 기반 서비스 배포를 위한 이미지 저장소
04. Netflix OSS

-
MSA를 실질적으로 구현하기 위해서 많은 기반 지식들의 대해서 알아봤다. 하지만 실질적으로 MSA를 구현하라고 하면 이러한 지식만 가지고 구현하기 힘들다. 하지만 Netflix OSS를 통해서 구현하면 쉽게 MSA를 구현할 수 있다.
-
Netflix OSS는 Netflix Open Source Software의 약자로서 Netflix사에서 이전에 심각한 서버 장애를 겪은 이후로 신뢰성 있고 수평 확장 가능한 클라우드 시스템으로 이전하기 위한 MSA 전환 기술 노하우와 문제해결 방법을 공유한 오픈 소스이다.
-
아래 사진은 Netflix OSS에 대한 간략한 MSA 구성도 이다. 이 구성도를 통해서 각 오픈소스에 대해서 소개하겠다.
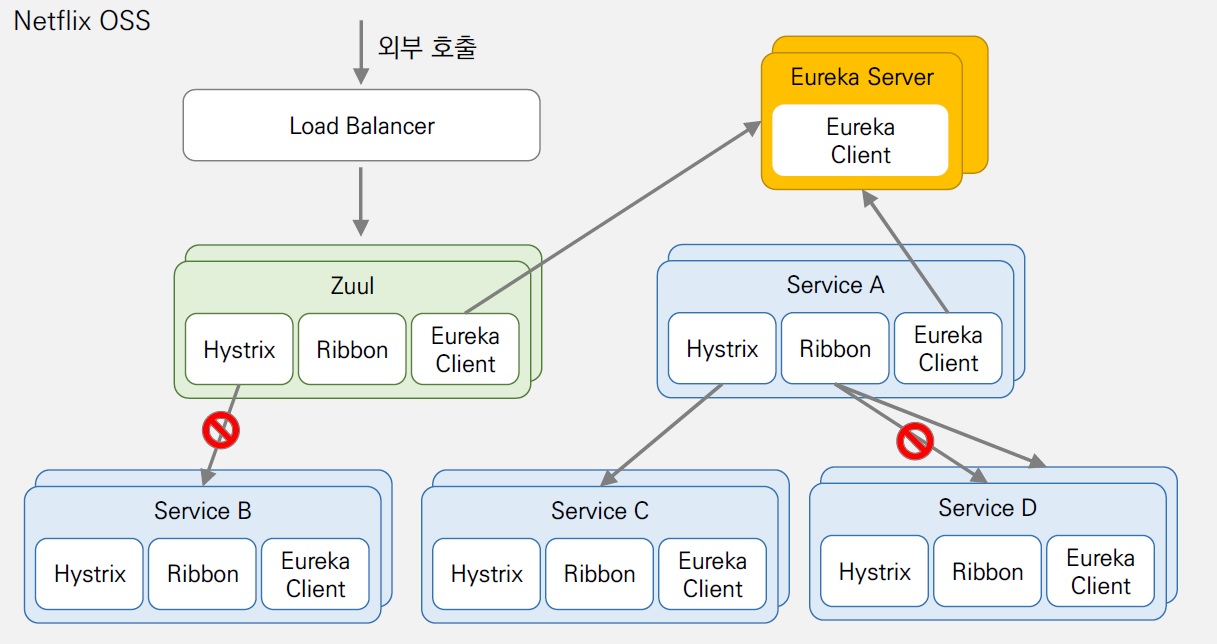
01) Eureka
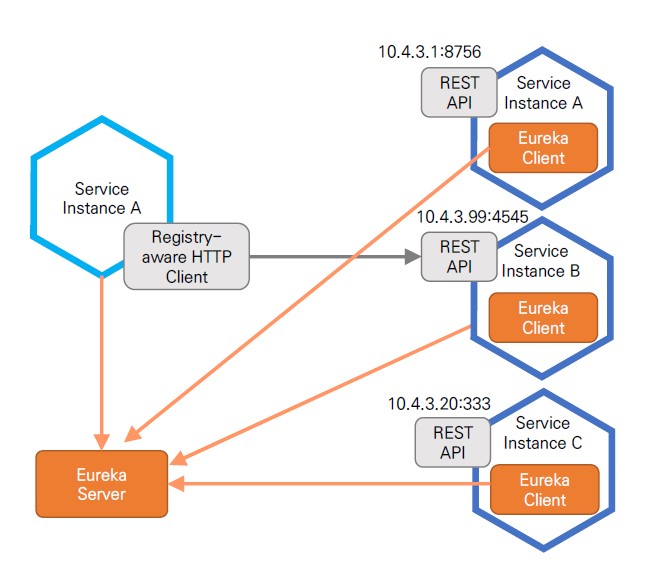
-
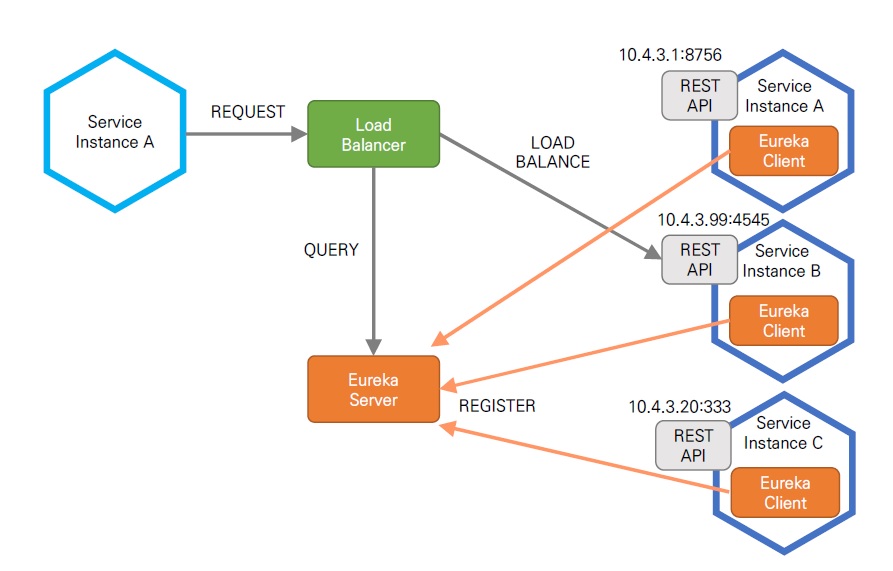
Eureka는 Service Discovery 와 Service Repository 역할하는 오픈소스로서 동적으로 변경되는 서비스 인스턴스들의 엔드 포인트를 관리한다.
-
Eureka는 서버와 클라이언트로 구성되어 있으며 클라이언트는 각 서비스 인스턴스에 내장되어 서비스 인스턴스 생성 시 서버에 등록한다. Eureka Server는 30초 마다 Helth Check를 통해서 각 서비스 인스턴스들이 살아있는지 확인하며 각 Client(Endpoint)를 관리한다. 이러한 방식을 Client Side Discovery라고 한다.
02) Ribbon
-
Ribbon은 Client Side Load Balancer로 여러 방식의 로드밸런싱을 제공해주며 서비스 통합 검색 및 내결함성을 위한 기능들을 제공하고 있다.
-
Client Side Load Balancing은 물리적인 장비를 통하지 않고 클라이언트 프로그램만으로만 로드 밸런싱하는 방법을 말한다. 유연한 확장이 가능하며 동적으로 설정이 가능하다.
-
Ribbon 아래와 같은 로드밸런싱 방법을 제공한다. 이를 Ribbon에서는 Rule라고 한다.
- Round Robbin : 한 서버 씩 돌아가면서 전달
- Available Filtering : 에러가 많은 서버 제외
- Weighted Response Time : 서버 별응답 시간에 따라 확률 조절
03) Zuul
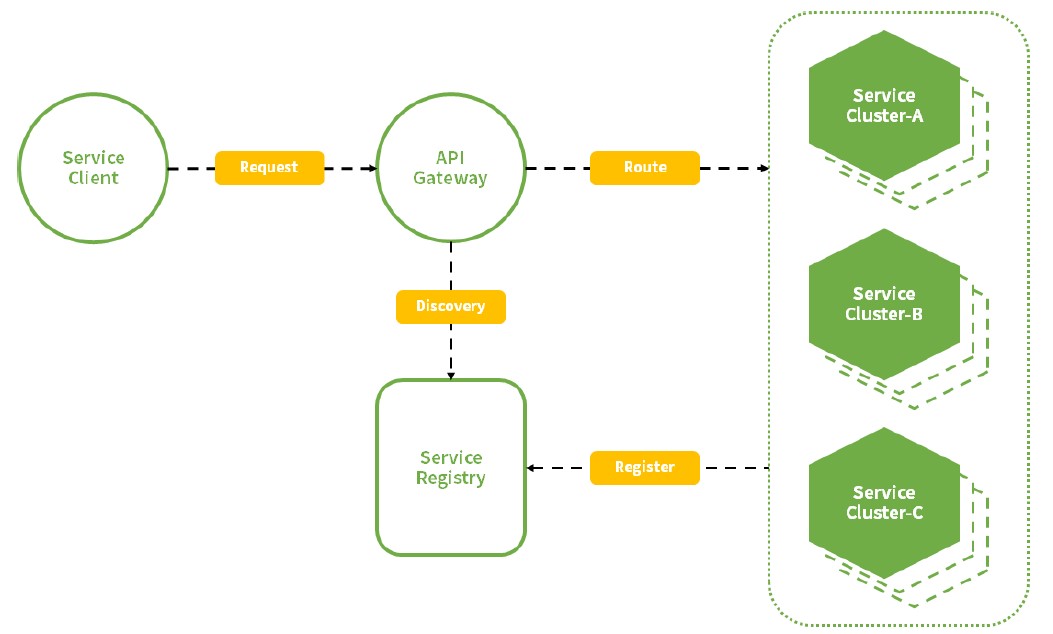
-
Zuul은 Netflix OSS에서 제공하는 API Gateway로서 API 통신 시 단일 포인트를 제공해주는 역할을 한다. Zuul을 단일으로 사용 가능하지만 보통은 Ribbon과 같이 사용하며 때로는 Euerka Server를 겸업할 수도 있다.
-
Zuul의 기능은 아래와 같다.
- Authentication and Security : 클라이언트 요청 시, 각 리소스에 대한 인증 요구 사항을 식별하고 이를 만족시키지 않는 요청은 거부
- Insights and Monitoring : 의미 있는 데이터 및 통계 제공
- Dynamic Routing : 필요에 따라 요청을 다른 클러스터로 동적으로 라우팅
- Stress Testing : 성능 측정을 위해 점차적으로 클러스터 트래픽을 증가
- Load Shedding : 각 유형의 요청에 대해 용량을 할당하고, 초과하는 요청은 제한
- Static Response Handling : 특정 요청에 대해서는 백엔드로 트래픽을 보내는 대신 즉시 응답하도록 구성 가능
05. 끝마치며
- MSA에 대한 얘기들은 더 많이 남았다. 지금까지 다룬 내용은 일부분일 뿐이다. MSA를 알기 위해서는 클라우드를 이해하고 있어야되고 이와 동반되는 주변 지식들이 필요하다. 그렇기 때문에 높은 러닝커브를 가진다. 하지만 이러한 기술들과 지식들은 필수가 되어가고 있으며, 이를 알고 활용할 줄 아는 개발자, 엔지니어가 되어야 한다. 이번에 클라우드 관련 포스팅을 하면서 내가 알고 있는 지식들이 아직도 많이 부족하다고 생각이 든다. 조금 더 유익하고 좋은 포스팅을 하기 위해서는 더많은 노력과 시간이 필요할듯 하다. 아무튼 이러한 포스팅을 읽어 주신분들께 감사를 드리며 이번 포스팅을 마치도록 하겠다.
댓글남기기