[AI] : Depth Anything V2
01. Depth Anything
1) Depth Anything
-
Depth Anything은 해당 논문에서 제안한 단안 깊이 추정(Monocular Depth Estimation)을 위한 솔루션이다. 기존 MiDaS에 비해서 좋은 성능을 보인다고 논문에서 설명하고 있다. Depth Anything은 성능 향상을 위해서 약 6200만 개의 대규모 레이블 없는 데이터를 수집하고, 자동 주석 시스템을 설계하여 데이터셋을 확장했다. 이로 인해 데이터 범위가 크게 확장되어, 모델의 일반화 오류를 줄일 수 있었다고 말하고 있다.
-
Depth Anything에서는 데이터 확장을 위해서 두가지 전략을 사용했다.
- 데이터 증강 도구 활용: 더 어려운 최적화 목표를 설정하여, 모델이 시각적 지식을 더 적극적으로 학습하고 견고한 표현을 형성할 수 있게 했다.
- 보조 감독 설계: 모델이 사전 훈련된 인코더에서 풍부한 의미적 지식을 상속받도록 강제하여, 더 나은 성능을 얻도록 했다.
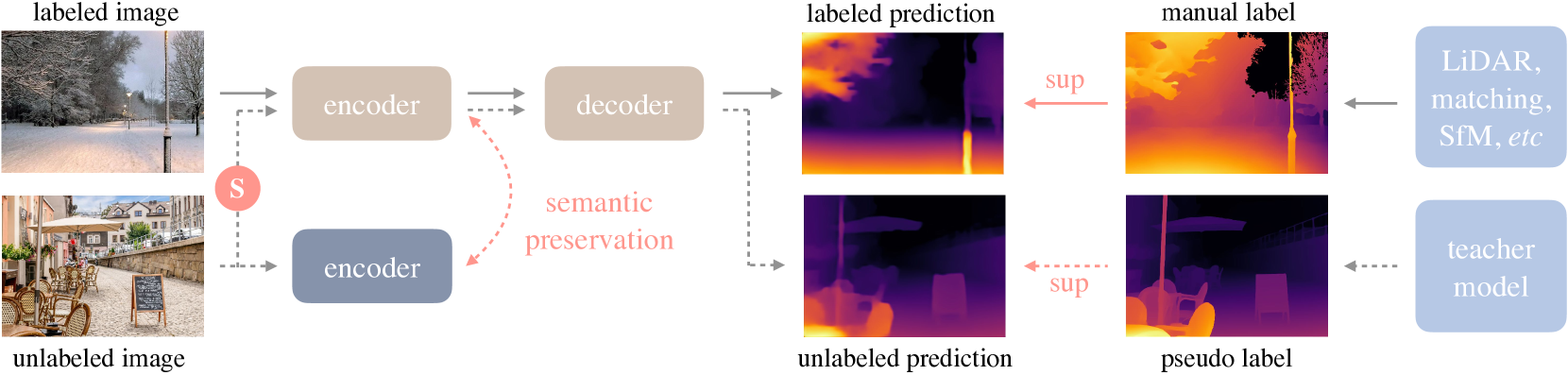
[참고: https://arxiv.org/abs/2401.10891]
- 단안 깊이 추정(Monocular Depth Estimation) : 단안 깊이 추정이란 단일 이미지에서 각 픽셀의 깊이(depth)를 추정하는 컴퓨터 비전 기술이다. 다른 고가의 장비(LiDAR, 스테레오 카메라 등)을 이용하지 않고 한 장의 2D 이미지로부터 3D 공간 정보를 유추하여, 이미지의 각 픽셀이 카메라로부터 얼마나 떨어져 있는지 계산한다. 이는 자율주행, AR 등 분야에서 사용된다.

[참고: https://arxiv.org/abs/2401.10891]
2) Depth Anything V2
- Depth Anything V2는 해당 논문에서 제안한 모델로써, V1보다 훨씬 더 세밀하고 강력한 깊이 예측을 제공한다. 이는 다음 세 가지 주요 변화 덕분이다.
- 모든 라벨이 있는 실제 이미지를 대체하여 합성 이미지로 훈련을 진행.
- 교사 모델(teacher model)의 용량을 확장.
- 대규모의 의사 라벨이 붙은 실제 이미지를 사용하여 학생 모델을 교육.
02. Depth Anything Fine Tuning
1) Fine Tuning
- Fine-Tuning(파인 튜닝)은 사전 학습된 모델을 기반으로 특정 작업에 맞춰 모델을 세부적으로 조정하는 기법이다. 일반적으로 대규모 데이터셋에서 미리 학습된 모델을 사용하고, 이를 특정 도메인에 적합하도록 소규모 데이터셋에서 재학습시키는 과정을 의미한다. Fine-Tuning은 특히 딥러닝에서 널리 사용되는 방법으로, 모델의 성능을 개선하면서 학습 시간을 단축하는 데 유용하다.
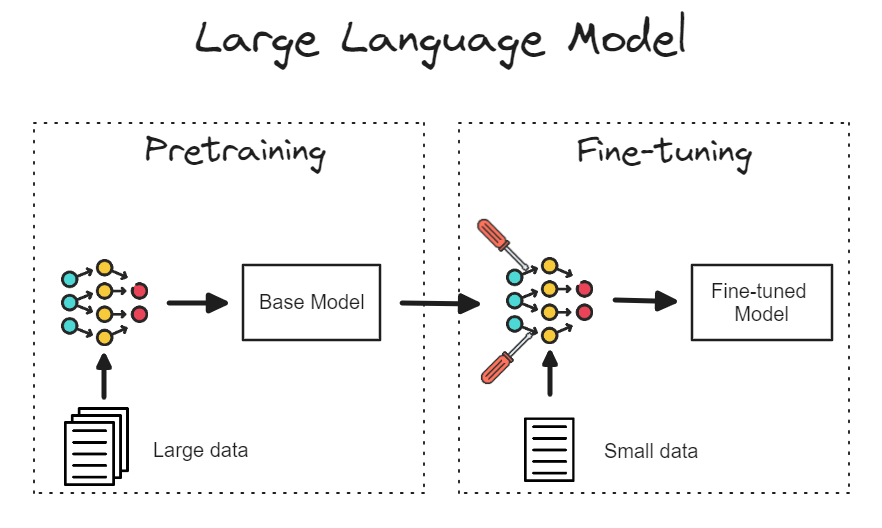
[참고: https://medium.com/@prasadmahamulkar/fine-tuning-phi-2-a-step-by-step-guide-e672e7f1d009 ]
2) Depth Anything Fine Tuning
- Depth Anything은 파인 튜닝은 해당 링크를 참고하였다. 데이터셋이 크니, 처음 수행할때는 Data를 Subnet 하는 방식으로 테스트 하는게 좋다.
1단계: 저장소 복제 및 사전 훈련된 가중치 다운로드
!git clone https://github.com/DepthAnything/Depth-Anything-V2
!wget -O depth_anything_v2_vits.pth "https://huggingface.co/depth-anything/Depth-Anything-V2-Small/resolve/main/depth_anything_v2_vits.pth?download=true"
# kaggle 기준으로 예제가 짜여 있어서, 노트북 사용 시 아래 링크에서 데이터셋 가져와야함.
!wget http://datasets.lids.mit.edu/fastdepth/data/nyudepthv2.tar.gz
2단계: 필요한 모듈 가져오기
# 2단계: 필요한 모듈 가져오기
import numpy as np # Numpy는 다차원 배열 및 수학 함수 처리를 위한 라이브러리입니다.
import matplotlib.pyplot as plt # Matplotlib는 시각화 및 그래프 출력을 위해 사용됩니다.
import os # OS 모듈은 파일 시스템 경로를 처리하는 데 사용됩니다.
from tqdm import tqdm # Tqdm은 반복문 진행 상황을 시각화하는 진행 바를 제공합니다.
import cv2 # OpenCV는 이미지 및 비디오 처리를 위한 라이브러리입니다.
import random # 랜덤화 및 무작위 요소 추가를 위해 사용됩니다.
import h5py # HDF5 파일 형식을 처리하는 데 사용됩니다.
import sys
sys.path.append('/home/K2023511/MDE/Depth-Anything-V2/metric_depth') # 외부 모듈 및 경로를 추가하여 커스텀 함수 및 스크립트를 사용합니다.
from accelerate import Accelerator # Accelerate는 여러 장치에서 모델을 쉽게 학습할 수 있도록 도와줍니다.
from accelerate.utils import set_seed # 랜덤 시드 설정을 도와주는 유틸리티로, 실험 결과의 재현성을 높입니다.
from accelerate import notebook_launcher # 노트북 환경에서 Accelerate 학습을 실행할 수 있게 도와줍니다.
from accelerate import DistributedDataParallelKwargs # 분산 데이터 병렬 처리에서 추가 설정을 할 때 사용됩니다.
import transformers # Hugging Face transformers는 사전 훈련된 모델을 다루는 데 사용됩니다.
import torch # PyTorch는 딥러닝 모델 구현 및 학습에 사용되는 대표적인 라이브러리입니다.
import torchvision # Torchvision은 PyTorch에서 이미지 데이터를 처리하고 모델을 학습하는 데 도움을 줍니다.
from torchvision.transforms import v2 # torchvision.transforms는 이미지 데이터의 변형을 돕는 모듈입니다.
from torchvision.transforms import Compose # 여러 데이터 변형을 결합하는 도구입니다.
import torch.nn.functional as F # PyTorch에서 기본적으로 제공하는 함수형 API, 주로 손실 함수 및 활성화 함수로 사용됩니다.
import albumentations as A # Albumentations는 이미지 증강을 위해 사용되는 고성능 라이브러리입니다.
from depth_anything_v2.dpt import DepthAnythingV2 # Depth-Anything 모델의 버전을 가져옵니다.
from util.loss import SiLogLoss # SiLog 손실 함수는 깊이 추정의 로그 스케일 손실을 계산하는 데 사용됩니다.
from dataset.transform import Resize, NormalizeImage, PrepareForNet, Crop # 데이터셋의 이미지 전처리를 위한 다양한 변형 함수들입니다.
3단계: 교육 및 검증을 위한 모든 파일 경로 가져오기
# 3단계: 교육 및 검증을 위한 모든 파일 경로 가져오기
def get_all_files(directory):
all_files = []
# 지정된 디렉터리를 순회하면서 파일 경로를 리스트에 추가
for root, dirs, files in os.walk(directory):
for file in files:
all_files.append(os.path.join(root, file)) # 파일의 절대 경로를 리스트에 추가
return all_files
# 훈련 데이터 경로 가져오기 (여기서는 NYU Depth Dataset을 사용하고 있습니다. 경로는 필요에 따라 변경해야 합니다.)
train_paths = get_all_files('/home/K2023511/MDE/nyudepthv2/train') # 훈련 데이터 경로 설정
val_paths = get_all_files('/home/K2023511/MDE/nyudepthv2/val') # 검증 데이터 경로 설정
4단계: PyTorch 데이터 세트 정의
# 4단계: PyTorch 데이터 세트 정의
# NYU Depth V2 40k 샘플 세트를 사용합니다. 원본 NYU 데이터는 400k 샘플입니다.
class NYU(torch.utils.data.Dataset):
def __init__(self, paths, mode, size=(518, 518)):
self.mode = mode # 'train' 또는 'val' 모드를 설정합니다.
self.size = size # 입력 이미지 크기를 설정합니다.
self.paths = paths # 데이터 경로를 저장합니다.
net_w, net_h = size # 네트워크 입력 크기 (너비, 높이)를 설정합니다.
# 작가가 정의한 데이터 전처리 변환 리스트 (훈련 또는 검증 모드에 따라 다름)
self.transform = Compose([
# 이미지 및 깊이 맵을 재조정합니다.
Resize(
width=net_w,
height=net_h,
resize_target=True if mode == 'train' else False, # 훈련 모드일 때 타겟(깊이 맵)도 함께 조정
keep_aspect_ratio=True, # 종횡비를 유지합니다.
ensure_multiple_of=14, # 너비와 높이를 14의 배수로 만듭니다.
resize_method='lower_bound', # 가장 작은 크기에 맞게 조정합니다.
# 3차 방정식(세제곱 보간법, Cubic Interpolation)을 사용하여 새로운 픽셀 값을 계산. 이는 인접한 4x4 픽셀 영역을 참조하여 픽셀 값을 결정
image_interpolation_method=cv2.INTER_CUBIC, # 이미지 크기 조정에 사용되는 방법(Cubic interpolation)
),
# 이미지 정규화 (mean(평균)과 std(표준편차)를 기반으로)
NormalizeImage(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
PrepareForNet(), # 모델 입력에 맞게 준비
] + ([Crop(size[0])] if self.mode == 'train' else [])) # 훈련 모드일 때만 추가적으로 이미지를 자릅니다.
# 데이터 증강 (훈련 시에만 사용)
# 수평 반전, 색상 조정, 가우시안 노이즈 추가 등
self.augs = A.Compose([
A.HorizontalFlip(), # 이미지를 수평으로 뒤집습니다.
A.ColorJitter(hue=0.1, contrast=0.1, brightness=0.1, saturation=0.1), # 색상 변경
A.GaussNoise(var_limit=25), # 가우시안 노이즈 추가
])
# 데이터 항목을 가져오는 함수 (데이터셋에서 하나의 이미지와 깊이 맵을 반환)
def __getitem__(self, item):
path = self.paths[item] # 파일 경로를 가져옵니다.
image, depth = self.h5_loader(path) # HDF5 파일에서 이미지를 로드합니다.
if self.mode == 'train': # 훈련 모드일 경우
augmented = self.augs(image=image, mask=depth) # 데이터 증강을 적용합니다.
image = augmented["image"] / 255.0 # 이미지를 0-1 사이로 스케일링합니다.
depth = augmented['mask'] # 깊이 맵을 동일하게 유지합니다.
else: # 검증 모드일 경우
image = image / 255.0 # 이미지를 0-1 사이로 스케일링합니다.
# 이미지와 깊이 맵에 변환을 적용합니다.
sample = self.transform({'image': image, 'depth': depth})
sample['image'] = torch.from_numpy(sample['image']) # 이미지 데이터를 텐서로 변환
sample['depth'] = torch.from_numpy(sample['depth']) # 깊이 맵 데이터를 텐서로 변환
# 깊이 맵의 유효 마스크를 반환할 수도 있습니다 (유효한 깊이 값만 처리할 때 사용)
# sample['valid_mask'] = ...
return sample # 전처리된 이미지와 깊이 맵 반환
# 데이터셋의 크기 반환 (데이터 경로의 길이로 결정)
def __len__(self):
return len(self.paths)
# HDF5 파일에서 이미지를 로드하는 함수
def h5_loader(self, path):
h5f = h5py.File(path, "r") # HDF5 파일을 읽기 모드로 엽니다.
rgb = np.array(h5f['rgb']) # RGB 이미지를 불러옵니다.
rgb = np.transpose(rgb, (1, 2, 0)) # 이미지를 (H, W, C) 형식으로 변환합니다.
depth = np.array(h5f['depth']) # 깊이 맵을 불러옵니다.
return rgb, depth # RGB 이미지와 깊이 맵을 반환합니다.
5단계: 데이터 시각화
# 5단계: 데이터 시각화
num_images = 5 # 시각화할 이미지와 깊이 맵의 개수를 5개로 설정합니다.
fig, axes = plt.subplots(num_images, 2, figsize=(10, 5 * num_images)) # 5행 2열의 subplot을 생성하여 각 이미지를 시각화할 공간을 만듭니다.
train_set = NYU(train_paths, mode='train') # 'train' 모드로 NYU 데이터셋을 불러옵니다.
for i in range(num_images): # 설정한 5개의 이미지에 대해 반복합니다.
sample = train_set[i*1000] # 데이터셋에서 1000번째 간격으로 샘플을 선택합니다.
img, depth = sample['image'].numpy(), sample['depth'].numpy() # 이미지를 NumPy 배열로 변환하고, 깊이 맵도 NumPy 배열로 변환합니다.
mean = np.array([0.485, 0.456, 0.406]).reshape((3, 1, 1)) # RGB 채널별로 정규화에 사용된 평균값을 설정합니다.
std = np.array([0.229, 0.224, 0.225]).reshape((3, 1, 1)) # RGB 채널별로 정규화에 사용된 표준 편차 값을 설정합니다.
img = img*std+mean # 이미지를 역정규화하여 원본 색상으로 복원합니다.
axes[i, 0].imshow(np.transpose(img, (1, 2, 0))) # 이미지를 (Height, Width, Channel) 형식으로 변환하여 올바르게 표시합니다.
axes[i, 0].set_title('Image') # 첫 번째 열에 이미지를 나타내는 제목을 설정합니다.
axes[i, 0].axis('off') # 이미지를 깔끔하게 보기 위해 축을 숨깁니다.
im1 = axes[i, 1].imshow(depth, cmap='viridis', vmin=0) # 깊이 맵을 viridis 색상으로 표시하고, 최소 깊이를 0으로 설정합니다.
axes[i, 1].set_title('True Depth') # 두 번째 열에 깊이 맵을 나타내는 제목을 설정합니다.
axes[i, 1].axis('off') # 깊이 맵의 축을 숨깁니다.
fig.colorbar(im1, ax=axes[i, 1]) # 깊이 맵 옆에 컬러바를 추가하여 색상 값과 실제 깊이 값의 관계를 표시합니다.
plt.tight_layout() # 그래프가 서로 겹치지 않도록 자동으로 레이아웃을 조정합니다.
6단계: Dataloader 준비
# 6단계: Dataloader 준비
from torch.utils.data import Subset
def get_dataloaders(batch_size):
# 사용할 데이터셋에서 첫 100개만 가져오기 (원하는 개수로 수정 가능)
# train_subset_size = min(10000, len(train_paths))
# val_subset_size = min(10000, len(val_paths))# 원하는 데이터 개수
# train_indices = list(range(train_subset_size)) # 첫 100개의 인덱스 생성
# val_indices = list(range(val_subset_size)) # 첫 100개의 인덱스 생성
# train_paths와 val_paths에서 일부 데이터만 가져오도록 Subset 사용
# train_dataset = Subset(NYU(train_paths, mode='train'), train_indices)
# val_dataset = Subset(NYU(val_paths, mode='val'), val_indices)
train_dataset = NYU(train_paths, mode='train') # 훈련 데이터셋을 NYU 클래스에서 가져옵니다.
val_dataset = NYU(val_paths, mode='val') # 검증 데이터셋을 NYU 클래스에서 가져옵니다.
# 훈련 데이터 로더 생성
train_dataloader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, # 지정된 배치 크기로 데이터 로드
# shuffle=True, # 훈련 데이터를 매 에포크마다 섞음
shuffle=False, # 훈련 데이터를 매 에포크마다 섞음
num_workers=4, # 데이터를 병렬로 로드하기 위한 워커 수
drop_last=True # 배치 크기에 맞지 않는 마지막 배치는 버림
)
# 검증 데이터 로더 생성
val_dataloader = torch.utils.data.DataLoader(val_dataset,
batch_size=1, # 동적 해상도 평가를 위해 배치 크기를 1로 설정 (패딩 없음)
shuffle=False, # 검증 데이터는 섞지 않음
num_workers=4, # 데이터를 병렬로 로드하기 위한 워커 수
drop_last=True # 배치 크기에 맞지 않는 마지막 배치는 버림
)
return train_dataloader, val_dataloader # 훈련 및 검증 데이터 로더를 반환
7단계: 지표 평가 함수
# 7단계: 지표 평가 함수
def eval_depth(pred, target):
assert pred.shape == target.shape # 예측값(pred)과 실제값(target)의 크기가 같아야 함을 보장하는 확인 코드
thresh = torch.max((target / pred), (pred / target)) # 예측값과 실제값의 비율을 계산하고, 각 위치에서 최대값을 취함
d1 = torch.sum(thresh < 1.25).float() / len(thresh) # d1 지표: 비율이 1.25 미만인 요소들의 비율을 계산 (정확도를 나타냄)
diff = pred - target # 예측값과 실제값 간의 차이를 계산
diff_log = torch.log(pred) - torch.log(target) # 로그 공간에서의 차이를 계산 (상대적인 차이를 보기 위함)
abs_rel = torch.mean(torch.abs(diff) / target) # 절대 상대 오차(absolute relative difference)를 계산하여 오차의 비율을 측정
rmse = torch.sqrt(torch.mean(torch.pow(diff, 2))) # RMSE (Root Mean Squared Error) 계산: 제곱 오차의 평균을 구한 뒤 제곱근을 취함
mae = torch.mean(torch.abs(diff)) # MAE (Mean Absolute Error) 계산: 절대 오차의 평균을 구함
silog = torch.sqrt(torch.pow(diff_log, 2).mean() - 0.5 * torch.pow(diff_log.mean(), 2)) # SILog (Scale-Invariant Logarithmic Error) 계산: 로그 차이의 평균으로 스케일 불변 오차를 계산
return {'d1': d1.detach(), 'abs_rel': abs_rel.detach(), 'rmse': rmse.detach(), 'mae': mae.detach(), 'silog': silog.detach()}
# 계산된 평가 지표들을 딕셔너리 형태로 반환
8단계: 하이퍼파라미터 정의
# 8단계: 하이퍼파라미터 정의
# 미리 학습된 모델 가중치 파일 경로 설정 (Depth Anything 모델을 사용할 예정)
model_weights_path = '//home/K2023511/MDE/depth_anything_v2_vits.pth'
# 다양한 모델 설정을 저장한 딕셔너리
# 각 모델에 따라 encoder와 features 및 출력 채널 크기가 다름
model_configs = {
'vits': {'encoder': 'vits', 'features': 64, 'out_channels': [48, 96, 192, 384]}, # 'vits' 모델에 대한 설정
'vitb': {'encoder': 'vitb', 'features': 128, 'out_channels': [96, 192, 384, 768]}, # 'vitb' 모델에 대한 설정
'vitl': {'encoder': 'vitl', 'features': 256, 'out_channels': [256, 512, 1024, 1024]}, # 'vitl' 모델에 대한 설정
'vitg': {'encoder': 'vitg', 'features': 384, 'out_channels': [1536, 1536, 1536, 1536]} # 'vitg' 모델에 대한 설정
}
# 사용할 모델의 인코더 선택 (여기서는 'vits'를 사용)
model_encoder = 'vits'
# 최대 깊이 값 (깊이 예측에서 사용할 최대값)
max_depth = 10
# 배치 크기 설정 (한 번에 처리할 데이터의 수)
batch_size = 11
# 학습률(Learning Rate) 설정 (모델이 학습할 때 가중치를 조정하는 속도)
lr = 5e-6
# 가중치 감쇠(Weight Decay) 설정 (과적합을 방지하기 위해 가중치가 너무 커지지 않도록 하는 정규화 기법)
weight_decay = 0.01
# 학습할 총 에포크(Epoch) 수 설정 (전체 데이터셋을 몇 번 반복할 것인지 결정)
num_epochs = 10
# 웜업 에포크 설정 (학습 초기에는 천천히 시작하여 모델의 안정성을 높임)
warmup_epochs = 0.5
# 스케줄러의 학습률 변동 속도 설정
scheduler_rate = 1
# 모델의 기존 상태를 불러올지 여부 (이전에 저장한 상태가 있을 경우)
load_state = False
# 모델 체크포인트 저장 경로 설정
state_path = "/home/K2023511/MDE/cp"
# 최종 학습된 모델이 저장될 경로 설정
save_model_path = '/home/K2023511/MDE/model'
# 시드 설정 (무작위성을 제어하여 실험의 재현성을 보장)
seed = 42
# 혼합 정밀도 설정 (fp16은 16-bit 부동 소수점을 사용하여 메모리 사용을 최적화)
mixed_precision = 'fp16'
9단계: 모델 훈련 함수 정의
# 9단계: 모델 훈련 함수 정의
def train_fn():
# 시드를 설정하여 결과의 재현성을 보장
set_seed(seed)
# DDP 관련 설정을 위한 DistributedDataParallelKwargs 설정
ddp_kwargs = DistributedDataParallelKwargs(find_unused_parameters=True)
# 혼합 정밀도를 활성화하고 가속기 설정
accelerator = Accelerator(mixed_precision=mixed_precision,
kwargs_handlers=[ddp_kwargs])
# DepthAnythingV2 모델을 초기화, 인코더를 사전 학습된 가중치로 불러오고 디코더는 랜덤 초기화
model = DepthAnythingV2(**{**model_configs[model_encoder], 'max_depth': max_depth})
# 사전 학습된 가중치만 불러옴 (디코더는 무작위로 초기화)
model.load_state_dict({k: v for k, v in torch.load(model_weights_path).items() if 'pretrained' in k}, strict=False)
# 모델의 사전 학습된 부분과 새롭게 학습할 부분의 학습률을 다르게 설정
optim = torch.optim.AdamW([{'params': [param for name, param in model.named_parameters() if 'pretrained' in name], 'lr': lr},
{'params': [param for name, param in model.named_parameters() if 'pretrained' not in name], 'lr': lr*10}],
lr=lr, weight_decay=weight_decay)
# SiLogLoss 사용 (논문에 나온 손실 함수)
# 깊이 추정(deep estimation) 작업에서 사용되는 손실 함수로, 이미지로부터 깊이 맵을 예측할 때 예측 값과 실제 값 간의 차이를 계산하는 방식이다.
# 이 손실 함수는 스케일 불변성(scale-invariance)을 보장하면서 깊이 값을 예측하는 과정에서 발생할 수 있는 오류를 최소화하는 특징을 가짐.
criterion = SiLogLoss()
# 데이터 로더를 가져옴 (학습 및 검증 데이터 로더)
train_dataloader, val_dataloader = get_dataloaders(batch_size)
# 학습 스케줄러 설정 (코사인 스케줄러 사용)
scheduler = transformers.get_cosine_schedule_with_warmup(optim, len(train_dataloader)*warmup_epochs, num_epochs*scheduler_rate*len(train_dataloader))
# 모델, 옵티마이저, 데이터 로더 및 스케줄러를 가속화기에 준비시킴
model, optim, train_dataloader, val_dataloader, scheduler = accelerator.prepare(model, optim, train_dataloader, val_dataloader, scheduler)
# 기존 상태를 불러오는 경우 체크포인트를 로드
if load_state:
accelerator.wait_for_everyone()
accelerator.load_state(state_path)
# 최적의 검증 성능을 저장하기 위한 초기값 설정
best_val_absrel = 1000
# 학습 루프 시작
for epoch in range(1, num_epochs):
model.train()
train_loss = 0
for sample in tqdm(train_dataloader, disable=not accelerator.is_local_main_process):
optim.zero_grad()
img, depth = sample['image'], sample['depth']
# 모델 예측 수행
pred = model(img)
# 손실 계산 (유효한 깊이 값만 사용)
loss = criterion(pred, depth, (depth <= max_depth) & (depth >= 0.001))
# 역전파 수행
accelerator.backward(loss)
optim.step()
scheduler.step()
# 전체 손실 계산
train_loss += loss.detach()
# 학습 손실 계산
train_loss /= len(train_dataloader)
train_loss = accelerator.reduce(train_loss, reduction='mean').item()
# 모델 검증 모드로 전환
model.eval()
results = {'d1': 0, 'abs_rel': 0, 'rmse': 0, 'mae': 0, 'silog': 0}
accelerator.print(len(val_dataloader))
for sample in tqdm(val_dataloader, disable=not accelerator.is_local_main_process):
img, depth = sample['image'].float(), sample['depth'][0]
with torch.no_grad():
pred = model(img)
# 원본 해상도에서 평가
pred = F.interpolate(pred[:, None], depth.shape[-2:], mode='bilinear', align_corners=True)[0, 0]
# 유효한 마스크 설정 (0.001보다 크고 max_depth보다 작은 깊이 값만 사용)
valid_mask = (depth <= max_depth) & (depth >= 0.001)
# 현재 샘플의 지표 평가
cur_results = eval_depth(pred[valid_mask], depth[valid_mask])
# 결과를 업데이트
for k in results.keys():
results[k] += cur_results[k]
# 평균 결과 계산
for k in results.keys():
results[k] = results[k] / len(val_dataloader)
results[k] = round(accelerator.reduce(results[k], reduction='mean').item(), 3)
# 체크포인트 저장
accelerator.wait_for_everyone()
accelerator.save_state(state_path, safe_serialization=False)
# 검증 절대 오차(abs_rel)가 가장 낮은 경우 모델 저장
if results['abs_rel'] < best_val_absrel:
best_val_absrel = results['abs_rel']
unwrapped_model = accelerator.unwrap_model(model)
if accelerator.is_local_main_process:
torch.save(unwrapped_model.state_dict(), save_model_path)
# 현재 에포크 결과 출력
accelerator.print(f"epoch_{epoch}, train_loss = {train_loss:.5f}, val_metrics = {results}")
에러 발생 시 수행
# # RuntimeError: File /home/K2023511/MDE/model cannot be opened. 에러 발생시 수행
import os
save_dir = "/home/K2023511/MDE/"
save_model_path = os.path.join(save_dir, "model.pth")
# 디렉토리가 없으면 생성
if not os.path.exists(save_dir):
os.makedirs(save_dir)
10단계: Traning
# 10단계: Traning
#You can run this code with 1 gpu. Just set num_processes=1
# num_processes 값을 통해 사용할 GPU의 개수를 지정하여 사용 가능.
notebook_launcher(train_fn, num_processes=1)

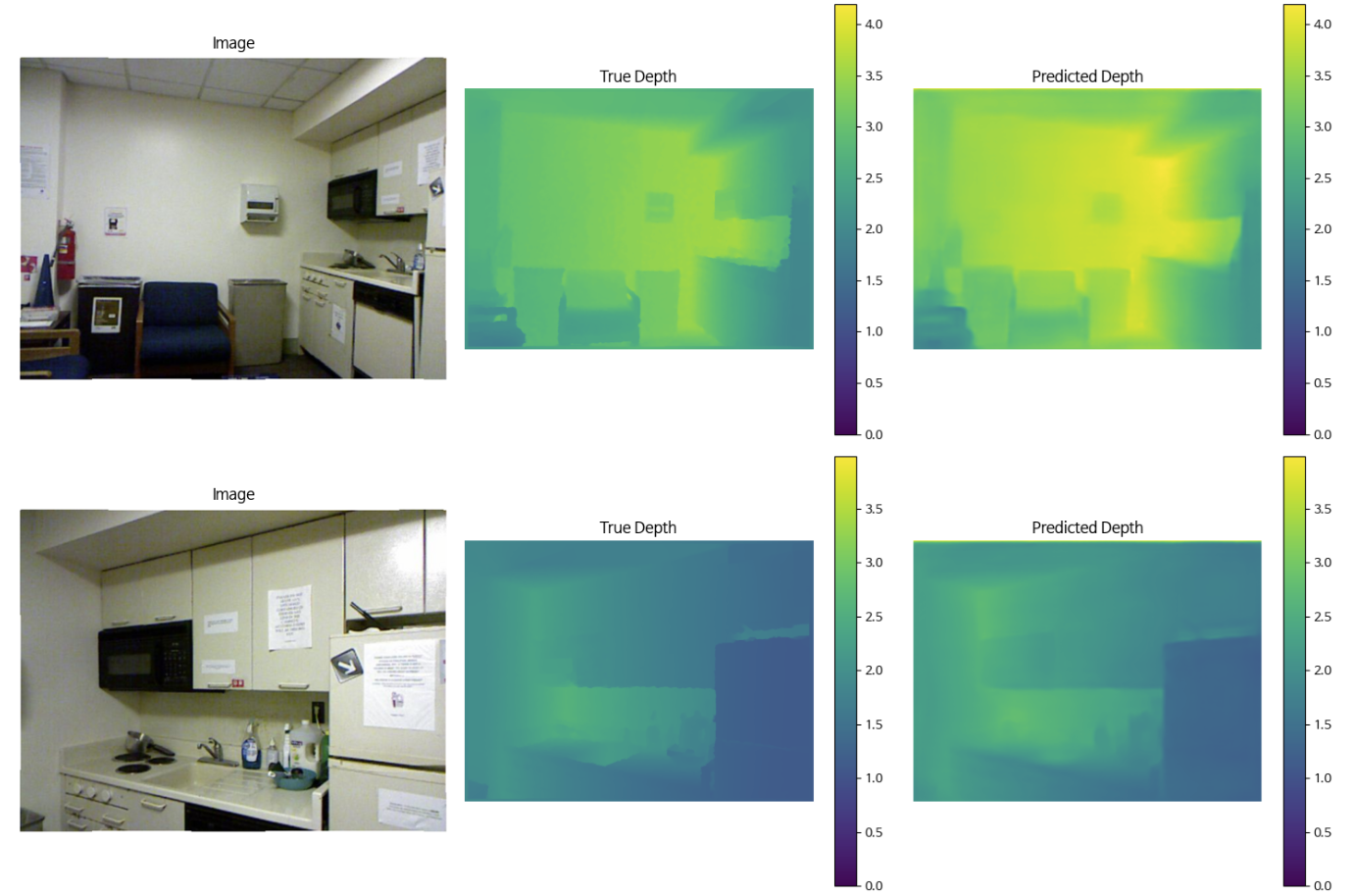
11단계 학습된거 실제로 확인해보기
# 모델 정의: 미리 정의된 DepthAnythingV2 모델을 max_depth 값과 함께 GPU로 로드
model = DepthAnythingV2(**{**model_configs[model_encoder], 'max_depth': max_depth}).to('cuda')
# 학습된 모델 파라미터를 로드하여 모델에 적용
model.load_state_dict(torch.load(save_model_path))
# 결과를 시각화할 이미지 수를 설정
num_images = 10
# 시각화를 위한 플롯 설정: 10개의 이미지에 대해 3개의 열을 가진 플롯(원본 이미지, 실제 깊이, 예측된 깊이)
fig, axes = plt.subplots(num_images, 3, figsize=(15, 5 * num_images))
# 검증 데이터셋 준비 (NYU Depth V2의 검증 데이터셋 사용)
val_dataset = NYU(val_paths, mode='val')
# 모델을 평가 모드로 전환 (이 때, 파라미터 업데이트는 발생하지 않음)
model.eval()
# 설정된 이미지 수(num_images)만큼 반복해서 결과 시각화
for i in range(num_images):
# 검증 데이터셋에서 i번째 샘플을 가져옴
sample = val_dataset[i]
img, depth = sample['image'], sample['depth']
# 이미지 정규화: 평균(mean)과 표준 편차(std)를 재적용하여 이미지를 원래 상태로 변환
mean = torch.tensor([0.485, 0.456, 0.406]).view(3, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).view(3, 1, 1)
# 모델 예측 수행: GPU에서 이미지를 입력으로 받아 깊이 맵을 예측
with torch.inference_mode():
pred = model(img.unsqueeze(0).to('cuda')) # 이미지 차원 추가 및 GPU로 이동
# 예측된 깊이 맵을 실제 깊이 맵의 해상도와 맞추기 위해 보간(interpolation) 수행
pred = F.interpolate(pred[:, None], depth.shape[-2:], mode='bilinear', align_corners=True)[0, 0]
# 이미지에 정규화를 다시 적용하여 시각화를 위해 복원
img = img*std + mean
# 첫 번째 열에 원본 이미지를 시각화
axes[i, 0].imshow(img.permute(1,2,0)) # 이미지 차원 변경 (채널을 마지막으로 이동)
axes[i, 0].set_title('Image') # 제목 설정
axes[i, 0].axis('off') # 축을 비활성화
# 최대 깊이를 실제 깊이와 예측된 깊이 중 가장 큰 값으로 설정
max_depth = max(depth.max(), pred.cpu().max())
# 두 번째 열에 실제 깊이 맵 시각화
im1 = axes[i, 1].imshow(depth, cmap='viridis', vmin=0, vmax=max_depth) # 컬러 맵 설정
axes[i, 1].set_title('True Depth') # 제목 설정
axes[i, 1].axis('off') # 축을 비활성화
fig.colorbar(im1, ax=axes[i, 1]) # 컬러바 추가
# 세 번째 열에 예측된 깊이 맵 시각화
im2 = axes[i, 2].imshow(pred.cpu(), cmap='viridis', vmin=0, vmax=max_depth) # 컬러 맵 설정
axes[i, 2].set_title('Predicted Depth') # 제목 설정
axes[i, 2].axis('off') # 축을 비활성화
fig.colorbar(im2, ax=axes[i, 2]) # 컬러바 추가
# 레이아웃을 조정하여 각 시각화가 서로 겹치지 않도록 설정
plt.tight_layout()
03. 끝마치며
- 이번 포스팅에서는 Depth Anything에 대해서 간단하게 알아보고 Fine Tuning하는 예제를 가져와 수행보았다. 이는 자료가 잘 정리되어 있어, 한국어 주석 처리와 실제 실습을 위해서 코드 수정해 놓았다. 혹시 더 필요한 내용이나 질문은 메일이나 댓글로 질문 바랍니다.
댓글남기기