[Text-to-SQL] : 01. Text-to-SQL
서론
- 이번에 AI 관련하여 연구를 진행했었던 Text-to-SQL에 대해서 얘기하고자 한다.
01. Text-to-SQL 이란?
1) Text-to-SQL
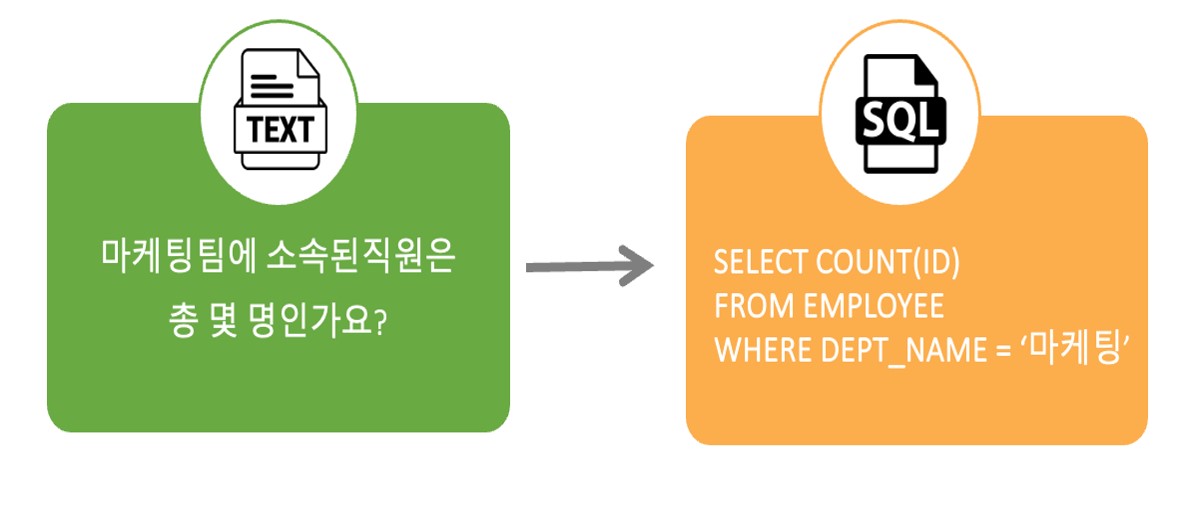
- Text-to-SQL은 사용자가 질의한 자연어를 데이터베이스가 이해할 수 있는 SQL로 변환해주는 기술을 말한다. 이는 기존의 LLM이 학습된 데이터에서만 답을 찾는다는 단점을 보완할 수 있다. 또한 Text-to-SQL 통해서 실시간으로 정보를 조회할 수 있어서 기업의 의사결정에 중요한 역활을 할 수 있다.
-
보통 개발자들은 이러한 기술이 왜 필요한지 이해 못할 수도 있다. 왜냐하면 일반 개발자는 SQL을 작성하는것이 직관적이고 원하는 데이터를 바로 찾아 컨트롤할 수 있다는 점이 훨씬 편하게 느껴지기 때문이다. 하지만 이러한 기술은 비개발 직군이 사용하기 좋은 기술이다. 특히 마케팅과 같이 실제 사용자 데이터를 알고 싶을때 기존에 만들어진 화면이나, 개발자에게 요청하여 데이터를 받아야 한다. 하지만 이또한 비용과 시간이 들기 때문에 의사결정 시간을 지연되고, 또한 비개발 직군에서 마음대로 데이터를 조회할 수 없다는 단점이 있다. 이때문에 요즘 비개발 직군에서도 R이나 Python 공부하는것이 이와 같은 문제에서 발생한다.
-
이러한 문제를 Text-to-SQL을 기반으로 한 사내 Chatbot이 있다면 바로 해결이 가능하다. 예를 들어 인사팀에서 “올해 입사한 20대 사원의 수를 알려줘” 라고 Chatbot에 질의하면 이를 기존의 학습된 데이터가 아니라 데이터베이스에서 바로 “SELECT COUNT(1) FROM 사원 WHERE 입사년도 = ‘2024’;”라고 조회하여 결과를 보여주게 된다. 이러한 활용성으로 인해 Text-to-SQL 기술으 필요성이 대두되고 있다.
02. Text-to-SQL 수행 순서
-
Text-to-SQL 수행 순서를 통해서 Text-to-SQL을 설명하고자 한다. 우선 Tex-to-SQL은 아래 사진과 같은 순서로 수행된다.
-
Text-to-SQL 수행순서
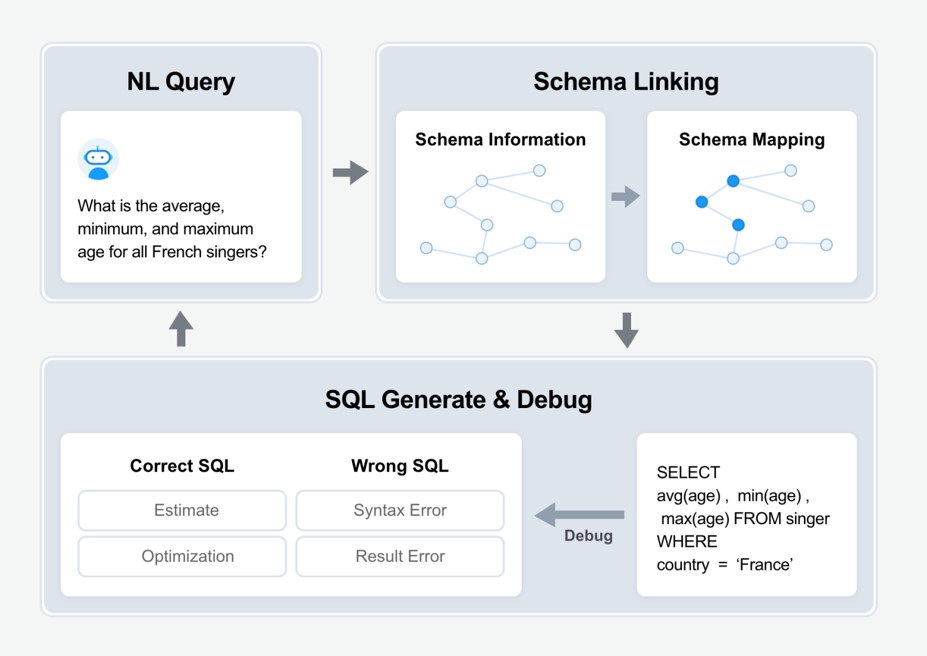
1) 사용자가 자연어를 질의
- 사용자가 실제 필요한 정보를 자연어로 질의하는 단계로 Input으로 들어오는 값이 자연어이다.
2) 질어의를 스키마 구조와 매칭
- 사용자가 질의한 자연어를 학습된 데이터베이스의 스키마 정보와 매칭한다. 예를 들면 “총 사용자의 수를 알려줘?”라고 질문했다면, 학습된 스키마 정보에서 “사용자”와 매칭되는 “USER”라는 스키마 정보를 매칭하는것이다. 이를 하나의 스키마 정보 뿐만이 아니라 스키마 끼리 관계 정보도 포함한다.
3) SQL 생성
- 이전에 매칭한 스키마 정보를 통해서 SQL을 생성한다. 스키마 구조를 통해서 조회할 테이블과 컬럼들을 선택하고 이를 통해서 SQL을 생성한다.
4) SQL 평가
- 생성된 SQL에 대해서 평가를 진행한다. SQL이 에러 없이 정상적으로 수행되는지 확인하고, 실제 결과가 올바르게 출력되는지 평가한다.
-
이와 같은 순서대로 Text-to-SQL을 진행하는데 여기서 중요한 부분은 사용자가 질의한 자연어를 정확하게 파악하여 학습된 스키마 정보와 매핑할것 인지이다. 이러한 부분들 때문에 자연어처리 기술을 필수적으로 활용된다.
-
자연어 처리를 대표적인 기술은 Seq2Seq, Transfomer 등이 있지만, 최근은 LLM 기반으로 많이 발전하고 있다. Text-to-SQL에서도 LLM을 이용한다.
03. Spider / WikiSQL Dataset
-
Text-to-SQL의 성능을 평가하기 위해서 많이 사용하는 데이터 셋은 Spider Dataset과 WikiSQL Dataset 두개 이다.
- Spider
- 예일대 11명의 대학생이 주석을 단 SQL 데이터셋.
- 10,181개의 질문으로 이뤄져 있음.
- 복잡한 SQL 쿼리를 포함한 다중 테이블에 대한 SQL 지원.
- Query Pair와 Haiving, Group by, limit, join 등 다양한 케이스 존재.
- SQL 난이도를 Easy, Medium, Hard, Extra Hard로 구분.
- WikiSQL
- Wekipedia의 24,241개의 테이블을 이용한 데이터셋.
- 80,654개의 샘플을 포함
- 단일 테이블에 대한 SQL만 존재하고 SELECT - WHERE 표현만 가능한 제한적인 구조만 가지고 있음.
04. 끝마치며
- 이번 포스팅에서는 Text-to-SQL에 대한 전반적인 얘기를 진행하였다. 다음 시간에는 Spider Dataset에서 1등(2024년 6월 기준)을 차지하고 있는 DAIL-SQL와 해당 논문에 대한 리뷰를 진행하고 한다. 다음 포스팅에서는 실제 Text-to-SQL이 어떤식으로 수행되는지 명확하게 이해하는 시간이 될수 있다.
댓글남기기