[Text-to-SQL] : 02. DAIL-SQL
서론
- 해당 포스팅에서는 DAIL-SQL 이라는 Text-to-SQL 방법론을 통해서 실제 Spider Dataset을 통한 Text-to-SQL을 수행하는 실습을 진행하고자 한다. Text-to-SQL에 대해서 알고 싶다면 이전 포스팅(Text-to-SQL)을 참고 바란다.
01. DAIL-SQL
1) DAIL-SQL이란?
-
DAIL-SQL은 Dawei Gao외 6명이 제안한 Text-to-SQL 방법론이다. 현재(2024-06)으로 86.6점으로 Spider Leaderboard에서 1등을 기록하고 있다.
-
특징으로는 MQS(Masked Question Similarity Selection)과 QRS(Query Similarity Selection)이라는 두가지 방법을 통해서 Few shot learning에 필요한 질문을 선택했다. 이러한 방법을 DAIL-Selection이라고 명칭하였고 이를 통해서 Few shot learning에 필요한 질문을 효율적으로 선택하였다.
-
MQS(Masked Question Similarity Selection)는 도메인 간 정보의 부정적 영향을 최소화하기 위해 질문 내의 테이블 이름, 열 이름, 값 등을 마스크 토큰으로 대체한다. 이들의 임베딩 유사성을 k-Nearest Neighbor(kNN) 알고리즘을 통해 계산하여 다양한 도메인에서의 적용 가능성을 높인다. 이를 통해 적합한 SQL을 효과적으로 선별할 수 있다.
-
QRS(Query Similarity Selection)는 타겟 SQL과 유사한 예제를 선택하는 과정에서 사전 모델을 활용하여 타겟 질문과 데이터베이스를 기반으로 초기 SQL을 생성한다. 생성된 초기 SQL을 근사값으로 사용하여 SQL의 키워드를 기반으로 이진 이산 구문 벡터로 인코딩한다. 근사된 SQL과의 유사성 및 선택된 예제들 간의 다양성을 고려하여 최적의 예제를 선정한다. 이러한 방법을 통해 DAIL-SQL은 다양한 도메인에서의 Text-to-SQL 변환을 효과적으로 수행하며, 최적의 SQL 쿼리를 선별할 수 있다
- 논문 링크 : https://arxiv.org/abs/2403.02951
2) LLM 활용
-
Text-to-SQL에서는 사용자의 질의어를 이해하기 위해서 LLM을 활용한다. DAIL-SQL을 제시한 논문에서는 GPT-4를 제안하였다. 아래 결과를 보면 GPT-4가 정확도가 높은것을 볼수 있다.
-
Spider Dev를 통한 결과
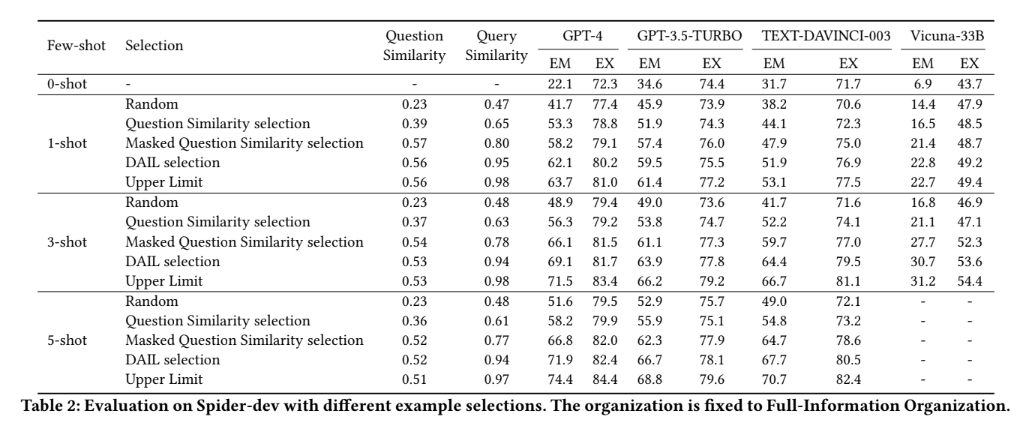
-
위의 표를 보게 되면 1-shot, 3-shot, 5-shot으로 구분하여 테스트를 진행하였다. 여기서 shot은 LLM에 질문할때 샘플을 몇개 보낼지 말한다. 1-shot은 1개의 샘플을 보내는것이다. 3-shot은 3개, 5-shot은 5개라고 생각하면 된다. 표와 같이 많은 샘플을 보낼수록 정확도가 높아지는것을 볼수 있다. 하지만 토큰 크기가 많아 지기 때문에 비용이 많이 든다는 단점이 있다. 이부분은 나중에 Few shot learning에 대해서 다시 포스팅 하도록 하겠다.
02. Spider Dataset
1) Spider Dataset 이란?
-
Spider Dataset은 예일대 대학생 11명이서 만든 Text-to-SQL Data set으로써 복잡한 SQL을 포함하며, 다중 테이블에 대한 조인 연산, Having, Group by 등 다양한 케이스를 제공한다. 또한 SQL 별 난이도를 Easy, Medium, Hard,Extra Hard로 나눠서 관리한다.
-
해당 데이터 셋은 Text-to-SQL 분야에서 제일 많이 활용하고 있는 데이터셋으로써 이를 통한 변형들이 많다. 해당 데이터셋의 지원은 올해 끝났지만 논문들이 해당 데이터셋으로 작성되어 이번 포스팅의 실습에서는 해당 데이터셋을 사용하도록 하겠다. 데이터셋이 궁금하면 Spider 로 가봐서 데이터를 확인해 보면 된다.
- 참고 링크 : https://yale-lily.github.io/spider
03. 실험
1) 실험 준비
- 실험 사양은 아래 표와 같다. 여기서 중요한거는 GPU의 RAM 크기가 중요하다. LLM을 활요하기 위해서는 RAM 크기가 중요하다. LLM을 사용하기 위해서는 GPU의 RAM을 사용하는데 RAM이 적을 경우 오류가 발생하기 떄문이다.
| 구분 | 사양 | 비고 |
|---|---|---|
| CPU | 4core | |
| DISK | 100GB | |
| GPU | RTX 3090, 24 GB | |
| Memory | 10GB | |
| LLM | Llama3-8B | 2024년 4월 출시 |
-
DAIL-SQL을 사용하기 위해서는 여기에서 code를 다운받으면 된다. 해당 소스는 DAIL-SQL에서 Llama3-8B를 사용하기 위한 수정한 소스이다.
-
해당 실험에서는 LLM을 GPT를 사용하지 않고 Llama3-8B를 활용한다. GPT는 비용이 너무 비싸기 때문에 무료로 사용 가능한 허깅페이스의 Llama3-8b의 API 를 활용한다.
2) DAIL-SQL 설치
- DAIL-SQL은 전체적인 설치는 github를 참고하면 되지만 필자가 겪었던 트러블슈팅까지 같이 진행하도록 하겠다. 우선은 필요한 jre,jdk를 다운 받는다.
cd sudo apt install default-jre -y sudo apt install default-jdk -y cd third_party/stanford-corenlp-full-2018-10-05 nohup java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer & cd ../../ - Python 환경 구성
conda create -n DAIL-SQL python=3.8 cd # 해당 부분 안하면 정상적으로 DAIL-SQL 적용이 되지 않음. source .bashrc conda activate DAIL-SQL python -m pip install --upgrade pip pip install -r requirements.txt python nltk_downloader.py - DAIL-SQL 설치
cd wget https://github.com/Im-Wali/Im-Wali-DAIL-SQL_jy/archive/refs/heads/main.zip unzip main.zip cd Im-Wali-DAIL-SQL_jy-main/
3) Spider dataset
- Spider dataset을 받아야 한다. 해당 파일은 Spider 에서 받으면 된다.
cd ~/Im-Wali-DAIL-SQL_jy-main mkdir dataset wget https://github.com/taoyds/spider/archive/refs/heads/master.zip unzip master.zip mv spider-master spider
4) 데이터 전처리
python data_preprocess.py
- 트러블 슈팅
# ERROR : AttributeError: 'CoreNLP' object has no attribute 'client' 발생 시 vi ~/.bash_profile export=CORELNP_HOME=/home/K2023511/third_party/stanford-corenlp-full-2018-10-05 # 추가
5) 프롬프트 생성
- few shot learning 위한 질문을 선택하는 순서이다.
python generate_question.py \ --data_type spider \ --split train \ --tokenizer llama3-8b \ --max_seq_len 4096 \ --selector_type EUCDISMASKPRESKLSIMTHR \ --prompt_repr SQL \ --k_shot 9 \ --example_type QA
6) LLM의 질의
- 4번에서 생성한 질의 들을 Llama3-8B에 질의하여 SQL을 리턴 받는다. 경우 따라서 다르지만 1000개의 Question을 진행했을때 20시간 걸렸다. 이부분은 Hugging face의 API 사용해서 그런 부분있으면 Llama3-8B가 모델 자체가 작아서 처리 속도가 느린것으로 생각이 든다.
python ask_llm.py \ --openai_api_key a \ --model llama3-8b \ --question ./dataset/process/SPIDER-TEST_SQL_9-SHOT_EUCDISMASKPRESKLSIMTHR_QA-EXAMPLE_CTX-200_ANS-4096/ \ --n 1 \ --db_dir ./dataset/spider/database \ --temperature 1.0
6) 평가
-
평가는 Spider에서 가이드주는 소스가 있다. 평가도 다른 소스를 사용하는 부분에서 조금 해맸지만 사용법은 어렵지 않다.
-
우선 해당 링크 에서 확인 가능하다.
- test-suite-sql-eval 설치
cd wget https://github.com/taoyds/test-suite-sql-eval/archive/refs/heads/master.zip unzip test-suite-sql-eval-master.zip - 필요 파일 설치
pip3 install sqlparse pip3 install nltk - 평가 진행
python evaluation.py \ --gold /home/K2023511/DAIL-SQL-main/dataset/spider/dev_gold.sql \ --pred /home/K2023511/DAIL-SQL-main/dataset/process/SPIDER-TEST_SQL_9-SHOT_EUCDISMASKPRESKLSIMTHR_QA-EXAMPLE_CTX-200_ANS-4096/RESULTS_MODEL-llama3-8b.txt \ --db "/home/K2023511/DAIL-SQL-main/dataset/spider/database" \ --etype all \ --table /home/K2023511/DAIL-SQL-main/dataset/spider/tables.json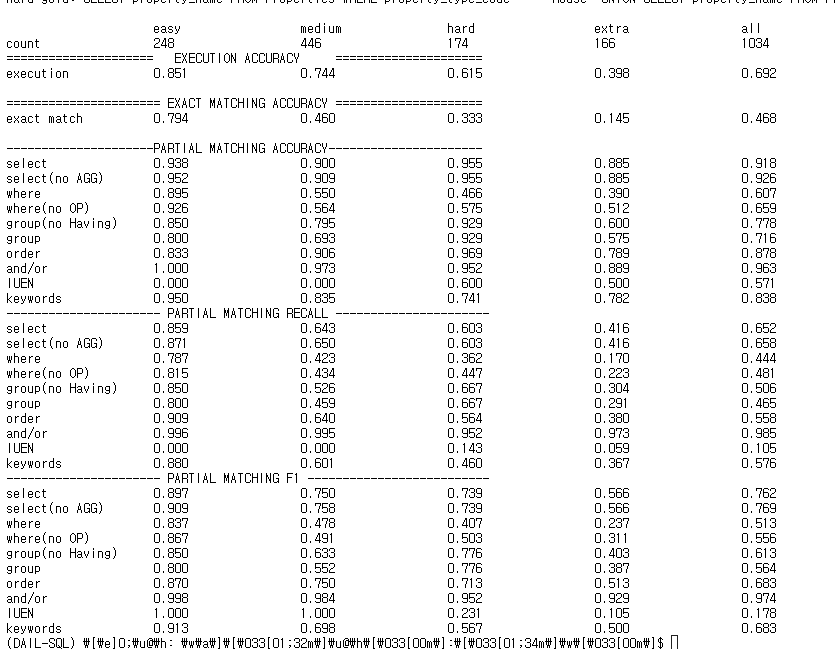
7) 평가지표
-
Spider에서는 평가지표로 EX와 EM을 사용한다. 평가지표는 EM(exact match accuracy)와 EX (Execution accuracy) 두가지로 구분하여 정확도를 측정한다.
-
EM(exact match accuracy)은 예측 SQL이 정답 SQL와 문자 단위로 얼마나 정확히 일치하는지 평가하는 지표이다.
-
EX (Execution accuracy) 는 SQL이 실제 수행된 결과를 비교하는 것으로 정답 SQL의 실행 결과와 예측 SQL의 결과가 같은지 측정하는 지표이다.
-
이 두가지 지표 중 EX를 더 중요하게 여긴다. 왜냐하면 다른 SQL이여도 동일한 결과를 내기 때문에 SQL 키워드가 정답 SQL 키워드와 상이해도 동일한 결과를 낼 수 있기 때문이다.
04. 끝마치며
- 해당 포스팅은 학술대회를 준비하면서 실험한 내용을 토대로 작성하였다. Text-to-SQL에서 LLM을 sLLM을 변경하여 어느정도의 성능이 나오는지 테스트하였고 동일한 조건의 GPT-4 보다 82.9% 성능을 유지하는것으로 실험 결과가 나왔다. 이번 실험으로 통해서 많은 삽질과 좌절이 있었지만 결과를 냈다는 점에서 의미를 얻어 간다. 해당 포스팅으로 궁금한 분은 언제 메일 주시면 감사하겠습니다.
댓글남기기