[AI] : 01. AI 역사와 발전 과정
서론
- 이번 포스팅에서는 정확하게 AI가 무엇이며, AI의 역사와 발전 과정에 대해서 알아보도록 하겠다.
01. AI
1) AI란?
- AI란? Artificial Intelligence의 약자로 인간의 학습 능력, 추력 능력, 지각 능력을 모방한 컴퓨터 과학의 분야의 한 분야이다. 예를 들면 사람은 고양이와 강아지를 종합적인 사고로 구분할 수 있다. 하지만 컴퓨터는 고양이와 강아지의 구분을 종합적인 사고를 통해서 구분 할 수 없다. 기존에는 사람이 직접 조건을 주어 구분하였다.(예: 수염의 길이가 00 이하는 고양이) 하지만 이 마저도 정확도가 떨어질 수 밖에 없었다. 이러한 문제를 해결 가능하도록 하는것이 AI 기술이다. AI기술을 사용하면 이전에 말로 정의하지 못했던 고양이와 강아지의 차이를 학습하여 최종적으로는 인간과 비슷한 수준으로 고양이와 강아지를 구분할 수 있게 되는것이다.
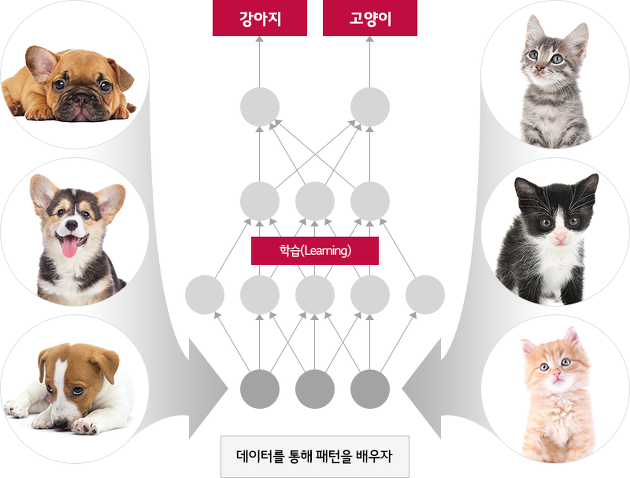
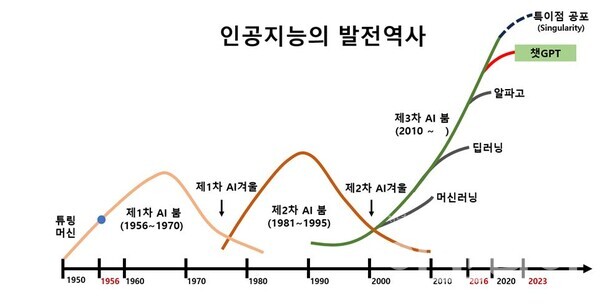
2) AI 역사와 발전 과정
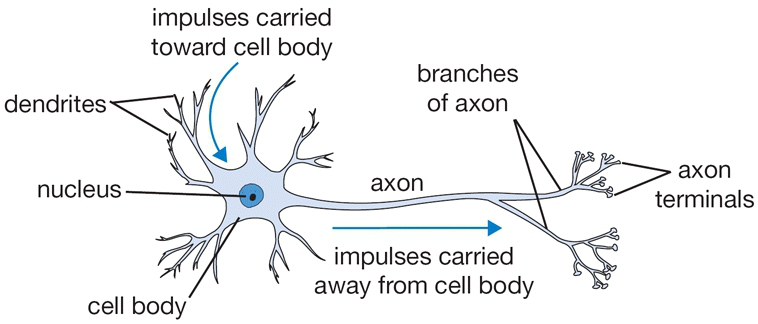
- AI 역사는 생각보다 길다. 이번 세션에서는 딥러닝 기준의 정리하고자 한다. 1943년 워렌 맥컬런과 월터 피트이 인간 두뇌에 대한 최초의 논리적인 모델을 제안하였다. 이 모델은 신경세포(뉴런)가 어떻게 동작하는지를 수학적으로 표현한 것으로, 이들이 발표한 논문 “A Logical Calculus of Ideas Immanent in Nervous Activity”에서 소개되었다.

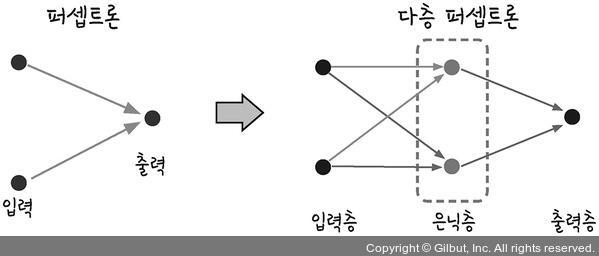
- 이후 1957년 플랭크 로제블럿이 최초의 신경망 모델인 “Perceptron”을 발표하였다. 이는 이후 신경망의 기초가 되는 개념이다. 퍼셉트론은 인간의 두뇌를 수학적으로 구성한것으로 뉴런의 자극 전달 구조를 모방하였다.
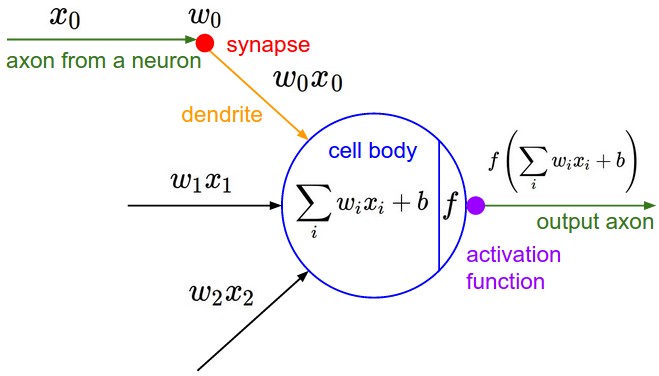
- 퍼셉트론은 다음과 같은 구조로 되어 있다. 입력층과 출력층으로 구분되며, 입력 신호(x)를 받아 출력 값(y)을 생성한다. 이때 w는 가중치(weight)라고 하며, 가중치를 조정하여 모델의 정확도를 높이는 것이 중요하다.
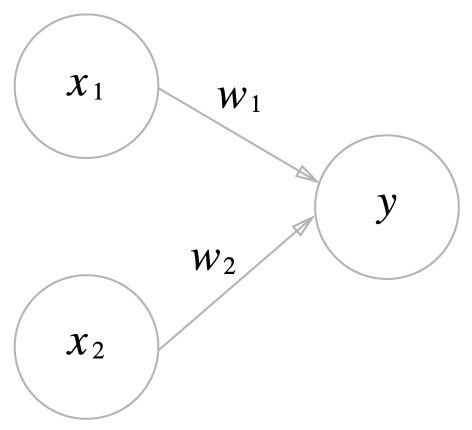
- 하지만 퍼셉트론은 태생적으로 한계가 있었다. XOR을 처리 못한다는 문제이다. 이러한 비선형 문제를 해결할 수 없어 인공지능의 암흑기가 한동안 지속 되었다.
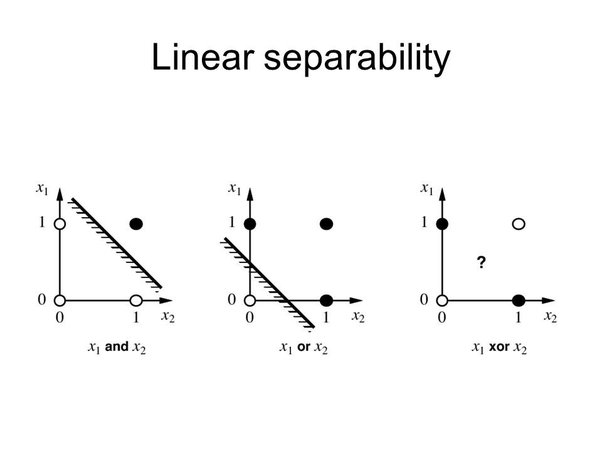
- XOR 문제를 해결하기 등장한 개념이 다층 신경망이다. 퍼셉트론이 하나일 때는 XOR 문제를 해결하지 못하지만 이를 두개 이상 쌓게 되면 XOR을 해결할 수 있다. 이를 통해 총 3개의 다층 신경망을 구현한것이다.
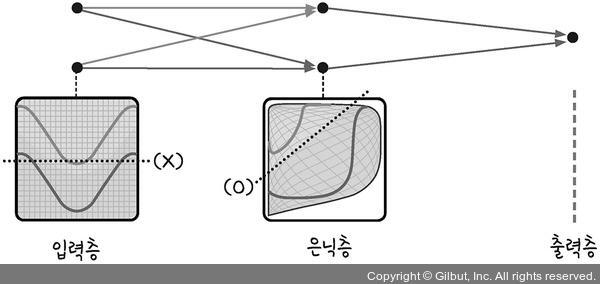
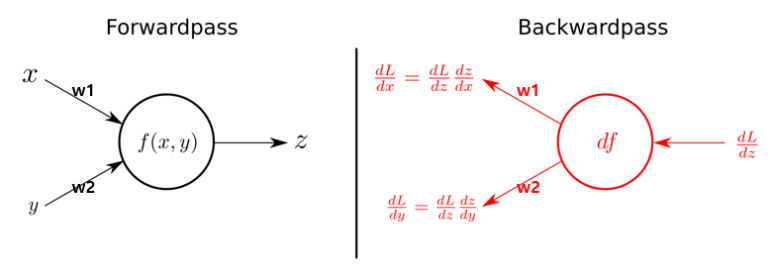
- 그리고 다층 신경망에서는 가중치를 효율적으로 업데이트하기 위해서 역전파 알고리즘을 사용한다. 역전파 알고리즘은 출력층과 기대값의 오차를 줄이기 위해서 가중치를 업데이트 하는 방식으로 일반적으로 입력층 -> 출력층 방향으로 오차를 수정하는 순전파 알고리즘과 다르게 입력층 <- 출력층 방향으로 오차를 역으로 전파하여 가중치를 업데이트 한다. 역전파_시뮬레이션
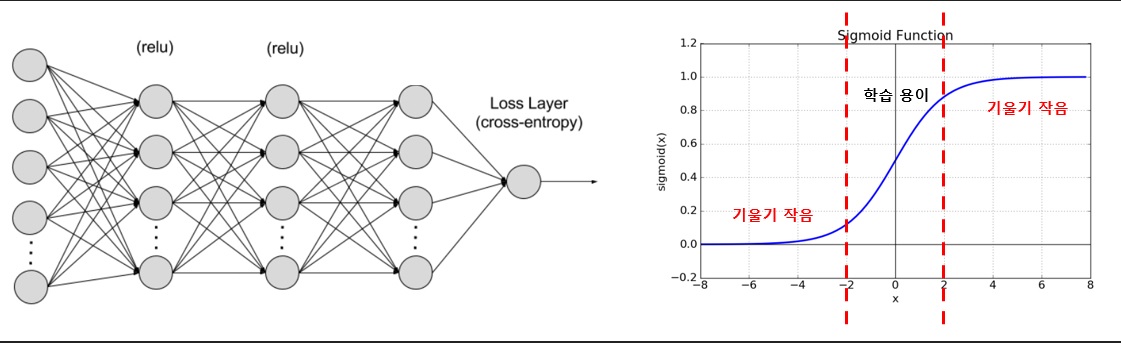
- 이후 또다른 문제로 인해 인공지능 분야의 암흑기가 시작되었는데, 암흑기를 가져온 문제는 기울기 소실(Vanishing gradient) 문제이다. 기울기 소실은 다층 신경망과 이를 학습 시키기 위한 알고리즘으로 인해 신경망의 크기가 커기지 시작했는데 이때 Layer가 일정 개수 이상 늘어나면 학습이 되지 않는 문제가 발생하였다.
다시 설명하자면 역전파 알고리즘 수행 시, 입력층에 가까워 질수록 기울기 급속적으로 작아져 기울기가 0에 수렴하는 문제이다. 0으로 수렴할 경우 더이상 학습을 진행할 수 없다.
-
이러한 기울기 소실 문제가 발생하는 제일 큰 원인은 활성화 함수(Activation Function)로 인한 것이다. 특히 Sigmoid 계열의 활성화 함수는 기울기 소실 문제에 취약했다.
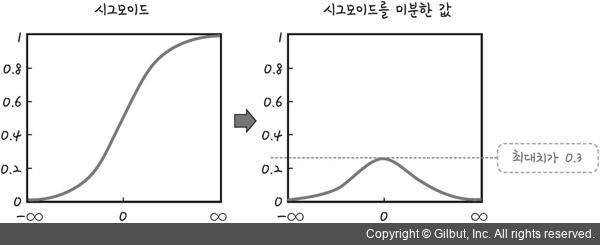
-
기울기 소실 문제를 해결하기 위해서 다양한 활성화 함수가 제안되었다.
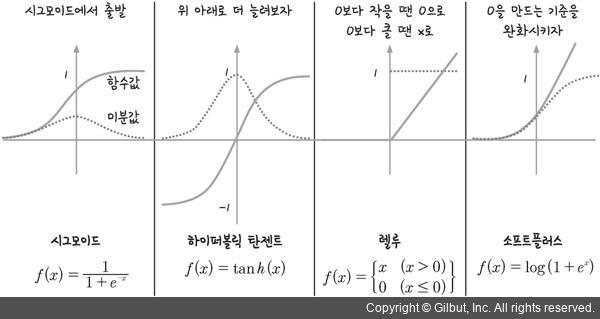
-
이러한 알고리즘의 발전과 급격한 컴퓨팅 파워의 증가와 데이터의 증가로 인해서 최근들어서 인공지능이 급격하게 발전하고 있다.
02. AI 구분
1) AI 구분
- 인공지능을 크게 구분하면 아래 사진과 같이 구분할 수 있다.

- 인공지능은 처음에도 얘기했던거 처럼 인간의 지능을 모방한 기술을 말한다.
- 머신러닝은 데이터를 분석하고 패턴을 인식하여 예측 모델을 만드는 기술이다. 알고리즘이 데이터로부터 학습하여, 새로운 데이터가 주어졌을 때 그에 대한 예측을 수행할 수 있도록 한다. 특징(feature)을 수동으로 선택하고, 이를 바탕으로 모델을 훈련한다. 대표적으로 Decision Tree, Regression, SVM이 있다.
- 딥러닝은 머신러닝의 하위 분야로써 특히 다층 신경망(Deep Neural Networks)을 사용하여 데이터로부터 자동으로 특징을 학습한다. 데이터로부터 자동으로 특징을 추출하며, 복잡한 패턴을 학습한다. 예를 들면 CNN, RNN 등이 있다.
- 생성형 AI는 최근 활발한 분야로 학습된 데이터를 통해서 신규 입력에 대한 새로운 데이터를 생성해주는 AI 분야이다. 대표적으로 LLM, GAN, VAE 등이 있다.
2) 학습 방법에 따른 구분
-
AI는 학습 방법에 따라서도 구분이 된다. 다른 포스팅에서 조금더 상세하게 다루도록 하겠지만 간단하게 설명하면 아래와 같다.
-
지도학습 : 지도학습은 입력(input)에 대한 실제 정답(Label)을 같이 학습 데이터로 사용하는 방법으로 정답을 사람이 직접 지정하기 때문에 명확하고 빠르게 학습할 수 있다는 장점이 있다. 하지만 정답을 사람이 맵핑 해줘야 하기 때문에 데이터셋을 만들때 많은 비용이 발생할 수 있다. 회귀(Regression), 분류(Classification) 문제에 효과적이다.
-
비지도학습 : 비지도학습은 입력에 대한 정답이 없는 학습 데이터로 학습하는 방법으로 입력의 패턴과 상관관계를 학습하는 형태의 학습 방법이다. 레이블링 작업이 필요 없어 레이블링 비용이 발생하지 않는다는 장점이 있다. 대표적인 방법으로는 군집(Clustering), Feature Extraction이 있다.
-
준지도 학습 : 정답이 있는 데이터(Labeled Data)와 정답이 없는 데이터(unlabeled Data)를 함께 학습 데이터로 사용하는 방법으로 지도 학습시에 정답(Label) 데이터가 부족할 경우 보안하기 위한 방법이다.
-
강화학습 : 강화 학습은 주어진 환경에 따른 보상으로 통해 학습을 진행하는 방법으로, 주체자(Agent)는 행동(action)에 대한 보상을 얻는다. 이 부분은 여기 로 가면 정확한 설명을 들을 수 있다.
03. 끝마치며
- 이번 포스팅에서는 AI 전체적인 역사와 발전 과정, AI에 대한 구분에 대해여 정리해보았다. 다음 포스팅 부터는 조금더 상세한 AI 기술/지식에 대한 부분을 포스팅하고자 한다.
댓글남기기